基于ZeroTier的SD WAN混合云组网方案验证
背景
以前曾个人玩法自建部署headscale进行组网,主要用于个人电脑(在外或在公司)能与家里群晖nas进行组网,解决随时从nas获取数据的需求。具体可看看过往的记录
今天我们的需求是企业场景,企业场景与个人场景略显不同,它主要是对混合云的组网,要求会更高。
这里的要求如下:
- 希望是完全私有化的方案,不允许有安全问题
- 希望能将腾讯云和自建IDC组网成混合云
- 希望组网后能互相访问内网不同的网段。
我们来验证一下ztnet能否做到以上这3点,为此我们先规划一下资源
- 腾讯云广州
- 腾讯云广州六区-qs服务器
172.16.32.16私有planet自建 - 腾讯云广州三区-scm服务器
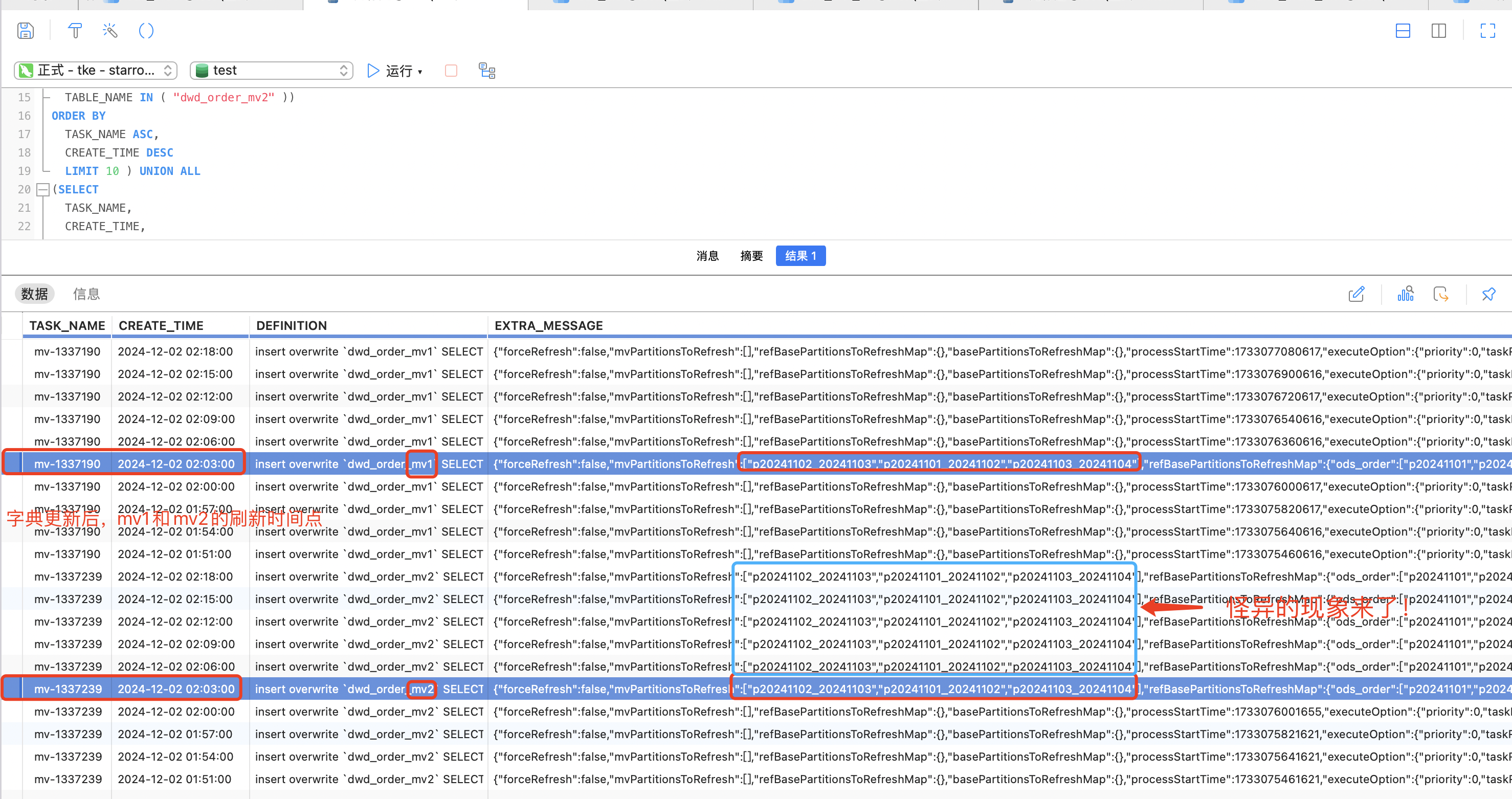
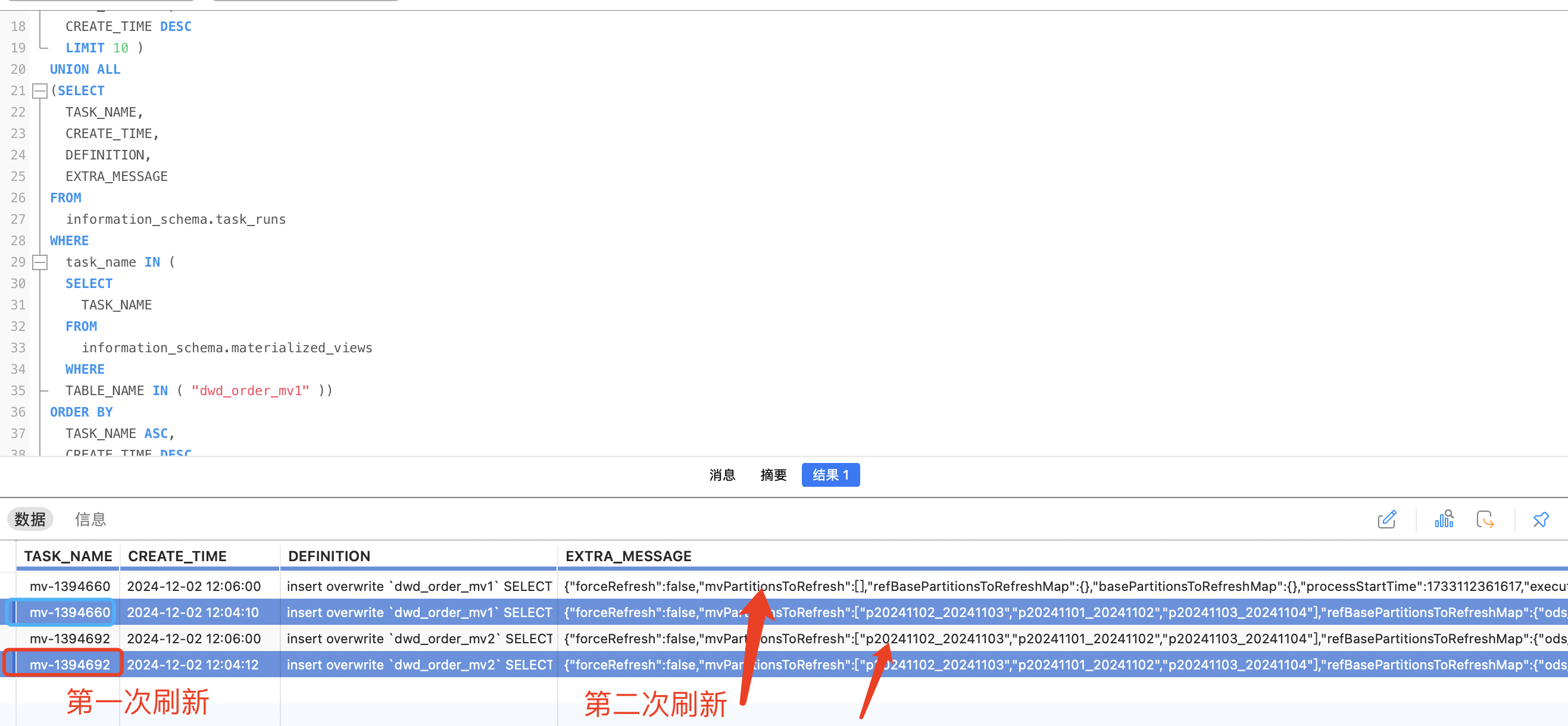
172.16.0.4leaf客户端 - 腾讯云广州三区-mysql服务
172.16.0.9:3306
- 腾讯云广州六区-qs服务器
- IDC机房
- 机房-data-center服务器
leaf客户端 - 机房-sqlserver数据库
- 机房-data-center服务器
验证
- ztnet部署
ztnet是zerotier私有根服务器的解决方案,解决根服务在别人手里的问题及根节点访问慢的问题
我们部署在腾讯云广州六区-qs服务器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100services:
postgres:
image: postgres:15.2-alpine
container_name: postgres
restart: unless-stopped
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: ztnet
volumes:
- postgres-data:/var/lib/postgresql/data
networks:
- app-network
zerotier:
image: zyclonite/zerotier:1.14.2
hostname: zerotier
container_name: zerotier
restart: unless-stopped
volumes:
- zerotier:/var/lib/zerotier-one
cap_add:
- NET_ADMIN
- SYS_ADMIN
devices:
- /dev/net/tun:/dev/net/tun
networks:
- app-network
ports:
- "9993:9993/udp"
environment:
- ZT_OVERRIDE_LOCAL_CONF=true
- ZT_ALLOW_MANAGEMENT_FROM=172.31.255.0/29
ztnet:
image: sinamics/ztnet:latest
container_name: ztnet
working_dir: /app
volumes:
- zerotier:/var/lib/zerotier-one
restart: unless-stopped
ports:
- 3000:3000
# - 127.0.0.1:3000:3000 <--- Use / Uncomment this line to restrict access to localhost only
environment:
POSTGRES_HOST: postgres
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: ztnet
NEXTAUTH_URL: "http://localhost:3000" # !! Important !! Set the NEXTAUTH_URL environment variable to the canonical URL or IP of your site with port 3000
NEXTAUTH_SECRET: "random_secret"
NEXTAUTH_URL_INTERNAL: "http://ztnet:3000" # Internal NextAuth URL for 'ztnet' container on port 3000. Do not change unless modifying container name.
networks:
- app-network
links:
- postgres
depends_on:
- postgres
- zerotier
############################################################################
# #
# Uncomment the section below to enable HTTPS reverse proxy with Caddy. #
# #
# Steps: #
# 1. Replace <YOUR-PUBLIC-HOST-NAME> with your actual public domain name. #
# 2. Uncomment the caddy_data volume definition in the volumes section. #
# #
############################################################################
# https-proxy:
# image: caddy:latest
# container_name: ztnet-https-proxy
# restart: unless-stopped
# depends_on:
# - ztnet
# command: caddy reverse-proxy --from <YOUR-PUBLIC-HOST-NAME> --to ztnet:3000
# volumes:
# - caddy_data:/data
# networks:
# - app-network
# links:
# - ztnet
# ports:
# - "80:80"
# - "443:443"
volumes:
zerotier:
postgres-data:
# caddy_data:
networks:
app-network:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.31.255.0/29