vmware esxi 显卡直通模式验证
背景
物理机器有显卡L20 (4 * 48G),安装vmware esxi系统,希望虚拟机rocky linux 10 直通物理显卡。
- vmware ESXi-8.0U2-22380479
- rocky linux 10
直通模式配置
vmware esxi 配置
由于ESXi 8.0没有对12代以后的CPU做默认的支持,所以在安装ESXi 8.0过程中会遇到紫屏的问题。为了解决这一问题,需要对ESXi的启动参数进行修改。
- 修改启动参数
在ESXi启动界面,按 Shift + O 进入启动选项编辑模式,然后添加以下参数:cpuUniformityHardCheckPanic=FALSE
完整的启动参数示例如下:kernelopt=… cpuUniformityHardCheckPanic=FALSE
- 修改启动参数
- 启动后通过SSH调整系统配置
启动进入ESXi系统后,通过SSH连接到主机,并执行以下命令以永久应用修改:此命令将启动参数持久化,确保每次启动ESXi时都应用该设置,防止紫屏问题再次出现。1
esxcli system settings kernel set -s cpuUniformityHardCheckPanic -v FALSE
- 启动后通过SSH调整系统配置
- 配置NVIDIA显卡直通
为了在虚拟机中成功直通NVIDIA显卡,还需要进行特定的配置
lspci -v | grep -i nvidia1
2
3
40000:81:00.0 Display controller 3D controller: NVIDIA Corporation Device 26ba
0000:82:00.0 Display controller 3D controller: NVIDIA Corporation Device 26ba
0000:c1:00.0 Display controller 3D controller: NVIDIA Corporation Device 26ba
0000:c2:00.0 Display controller 3D controller: NVIDIA Corporation Device 26balspci -v | grep -i nvidia -A11
2
3
4
5
6
7
8
9
10
110000:81:00.0 Display controller 3D controller: NVIDIA Corporation Device 26ba
Class 0302: 10de:26ba
--
0000:82:00.0 Display controller 3D controller: NVIDIA Corporation Device 26ba
Class 0302: 10de:26ba
--
0000:c1:00.0 Display controller 3D controller: NVIDIA Corporation Device 26ba
Class 0302: 10de:26ba
--
0000:c2:00.0 Display controller 3D controller: NVIDIA Corporation Device 26ba
Class 0302: 10de:26ba- 编辑ESXi配置文件:
通过SSH连接到ESXi主机,执行以下命令将显卡设备标记为直通设备:其中,1
2
3
4echo '/device/0000:c2:00.0/owner = "passthru"' >> /etc/vmware/esx.conf
echo '/device/0000:81:00.0/owner = "passthru"' >> /etc/vmware/esx.conf
echo '/device/0000:c1:00.0/owner = "passthru"' >> /etc/vmware/esx.conf
echo '/device/0000:82:00.0/owner = "passthru"' >> /etc/vmware/esx.conf0000:01:00.0为NVIDIA显卡的PCI地址,请根据实际硬件调整。 - 更新Passthru映射文件:
为了确保显卡的各项功能能够正确直通,需在passthru.map文件中添加相关配置。执行以下命令:这里的10de 26ba代表NVIDIA显卡的厂商ID和设备ID,请根据你的显卡型号进行相应调整。1
2
3echo '10de 26ba bridge false' >> /etc/vmware/passthru.map
echo '10de 26ba link false' >> /etc/vmware/passthru.map
echo '10de 26ba d3d0 false' >> /etc/vmware/passthru.map - 重启ESXi服务:
为使上述配置生效,需要重启ESXi的管理代理服务。执行以下命令:或者,您也可以选择重启整个ESXi主机。1
2/etc/init.d/hostd restart
/etc/init.d/vpxa restart
- 配置NVIDIA显卡直通
虚拟机配置
- 创建虚拟机及配置参数
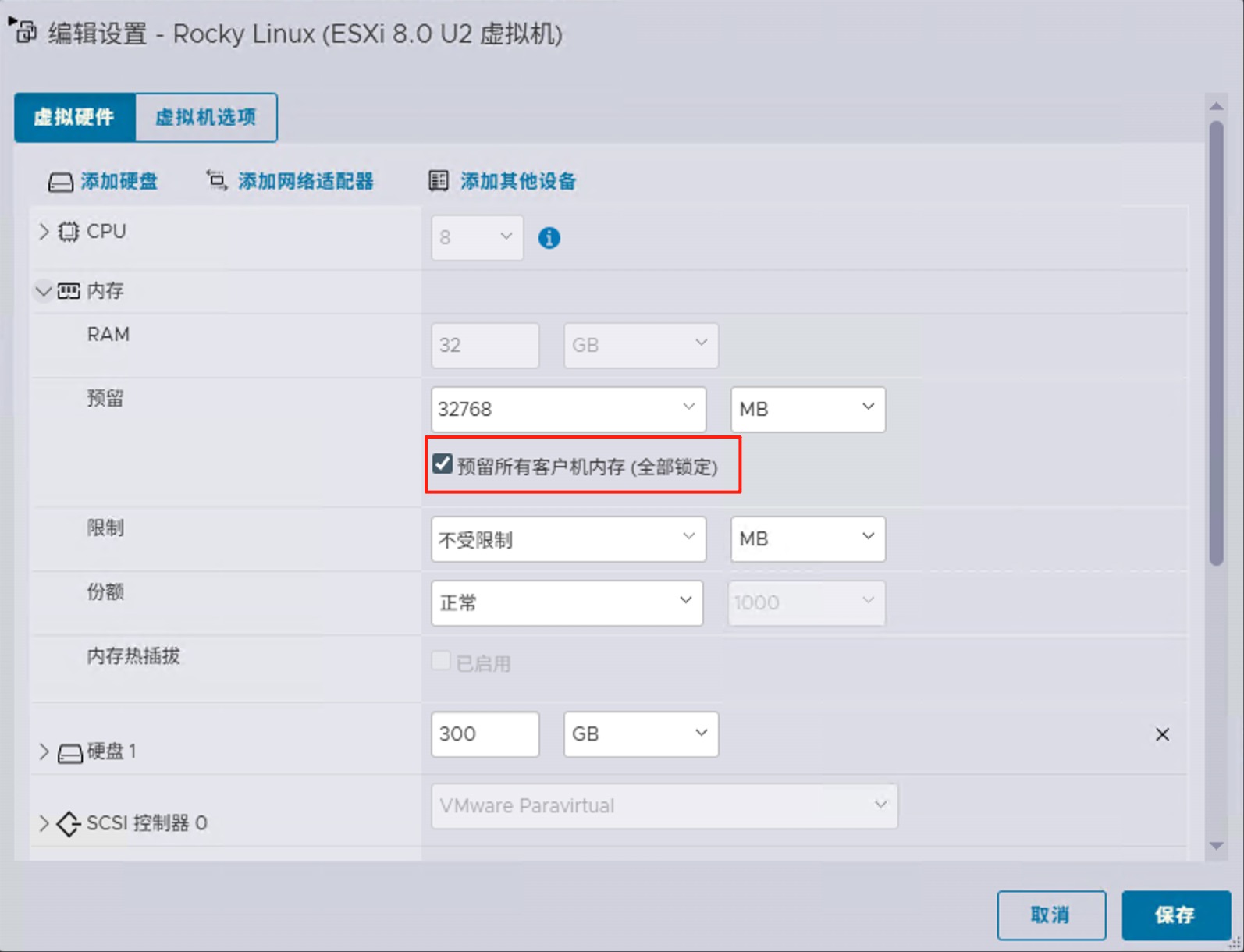
- 预留全部内存
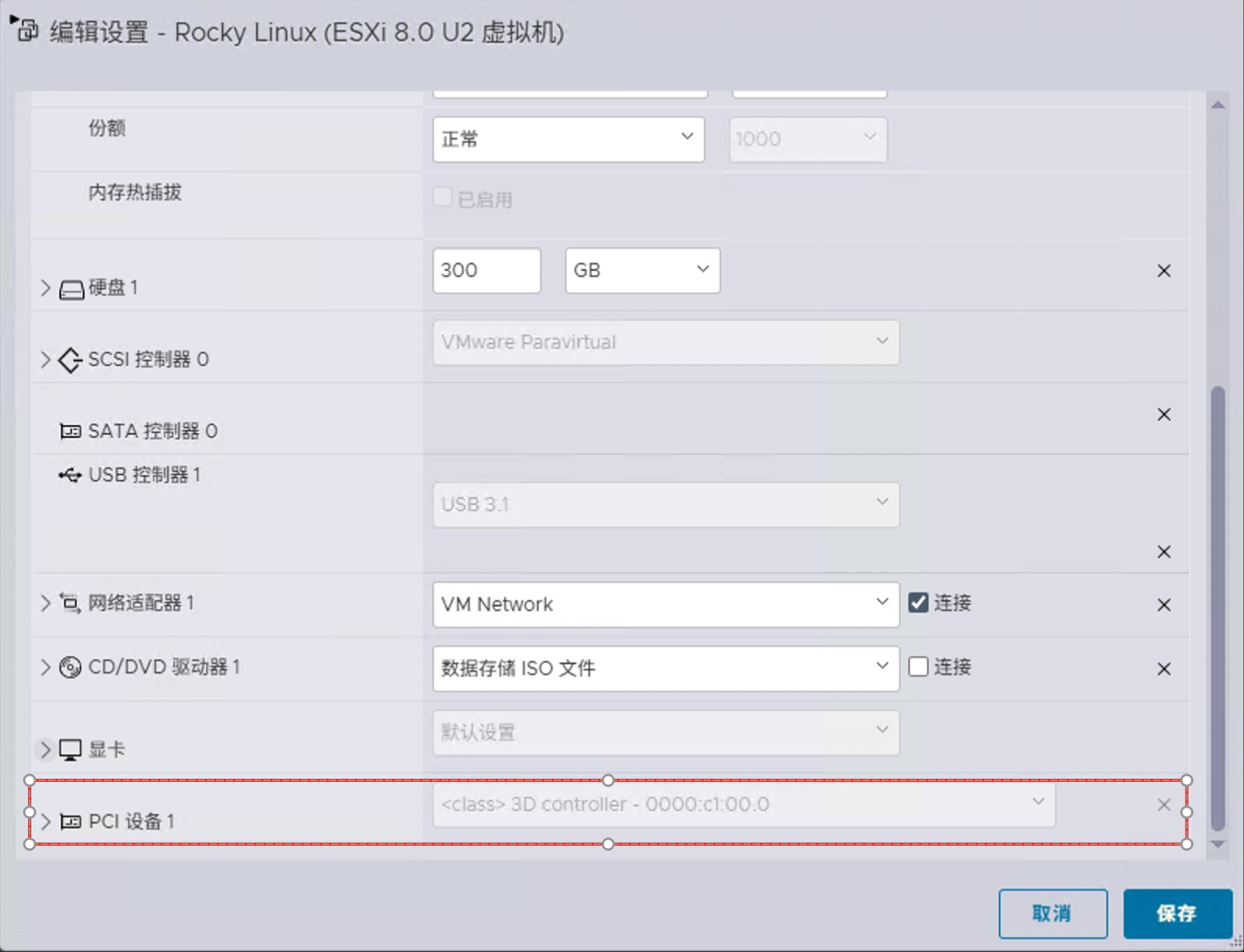
- 在“虚拟机设置”中,点击“添加其他设备” > “PCI设备”,在列表中找到并勾选NVIDIA显卡(例如,0000:c1:00.0)。
- 取消UEFI安全启动
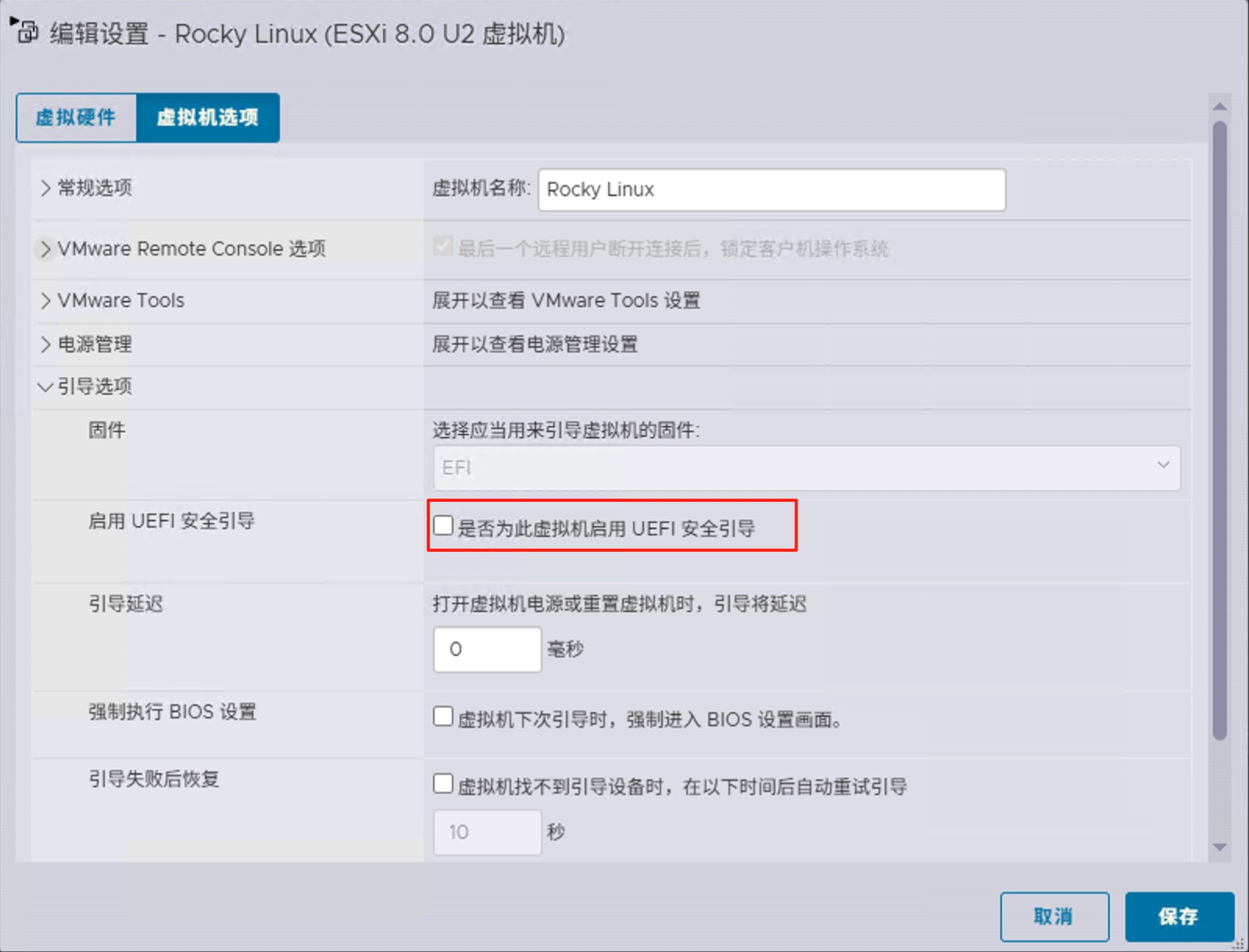
- 预留全部内存
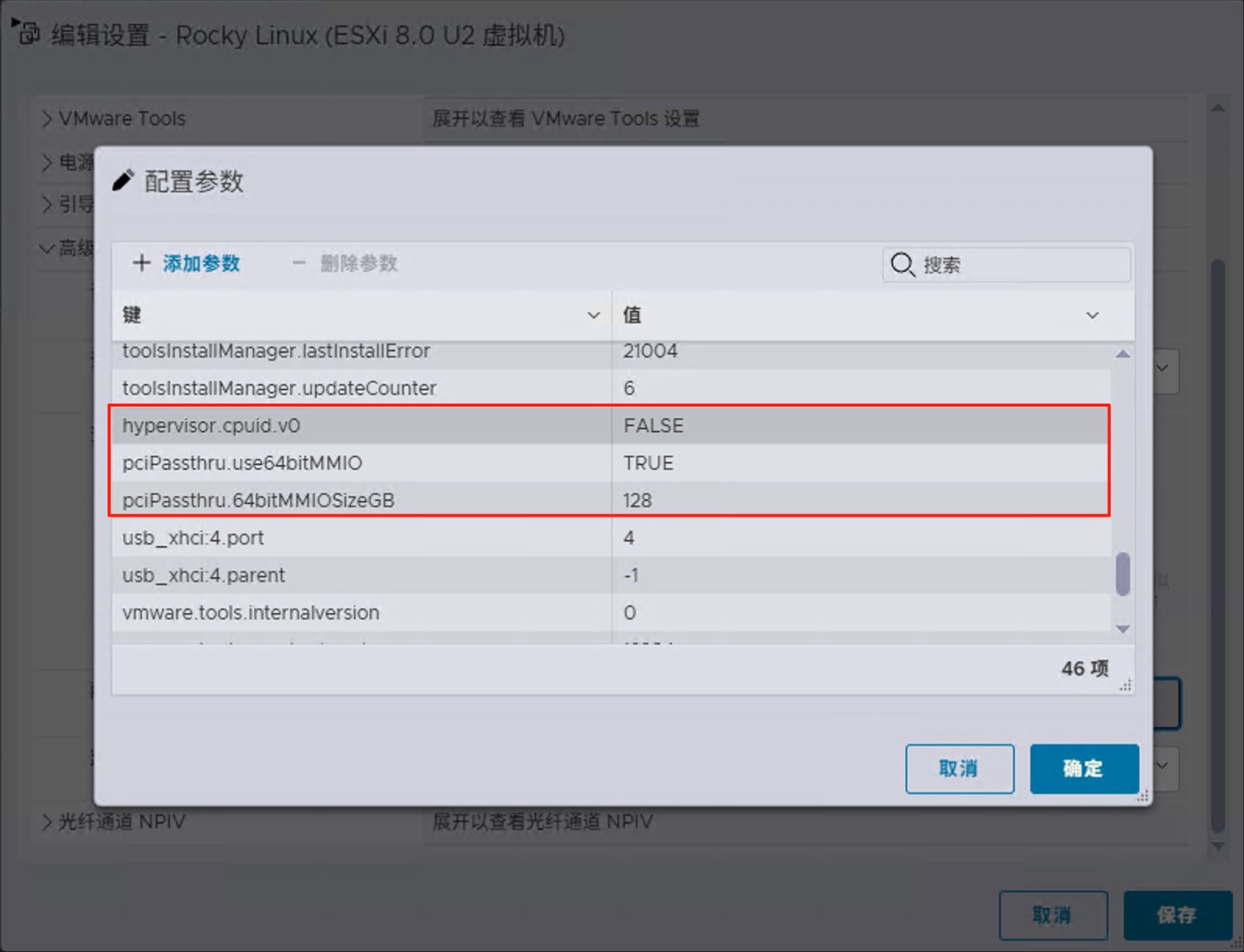
为了优化GPU直通的性能和兼容性,需要在虚拟机的高级配置中添加以下参数:
1 | 该参数用于隐藏虚拟化环境,使得虚拟机能够更好地识别并利用NVIDIA显卡。 |
pciPassthru.64bitMMIOSizeGB计算方式 https://earlruby.org/tag/use64bitmmio/
64bitMMIOSizeGB值的计算方法是将连接到VM的所有GPU上的显存总量(GB)相加。如果总显存为2的幂次方,则将pciPassthru.64bitMMIOSizeGB设置为下一个2的幂次方即可。
如果总显存介于2的2次方之间,则向上舍入到下一个2的幂次方,然后再次向上舍入。
2的幂数是2、4、8、16、32、64、128、256、512、1024…
例如虚拟机直通两张24G显存的显卡,则64bitMMIOSizeGB应设置为128。计算方式为24*2=48,在32和64之间,先舍入到64,再次舍入到128
linux 驱动安装
内核版本及更新
1
2uname -r
sudo dnf update -y安装基本开发工具
1
2sudo dnf install epel-release -y
sudo dnf groupinstall "Development Tools" -y内核制备
安装内核开发包;提高兼容性,安装与当前内核版本匹配的内核头文件
1
2sudo dnf install kernel-devel -y
sudo dnf install kernel-headers-$(uname -r) -y安装 Dynamic Kernel Module Support (DKMS)
DKMS 会在内核更新发生时自动重建内核模块,确保您的 NVIDIA 驱动程序在系统更新后仍然正常运行:
1
sudo dnf install dkms -y
将官方 NVIDIA CUDA 存储库添加到您的系统。对于 Rocky Linux 10,请使用 RHEL 9 兼容存储库:
1
2
3sudo dnf config-manager --add-repo http://developer.download.nvidia.com/compute/cuda/repos/rhel9/$(uname -i)/cuda-rhel9.repo
# 更新您的包缓存以识别新的仓库:
sudo dnf makecache在安装实际的 NVIDIA 驱动程序之前,请确保存在所有必要的依赖项:
1
sudo dnf install kernel-headers-$(uname -r) kernel-devel-$(uname -r) tar bzip2 make automake gcc gcc-c++ pciutils elfutils-libelf-devel libglvnd-opengl libglvnd-glx libglvnd-devel acpid pkgconfig dkms -y
禁用 Nouveau 驱动程序
Nouveau 驱动程序提供基本功能,但缺乏 CUDA 支持、最佳游戏性能和专业工作站功能等高级功能。专有的 NVIDIA 驱动程序提供完整的功能集和更好的性能优化。
使用 grubby 命令修改内核参数并将 Nouveau 驱动程序列入黑名单:1
sudo grubby --args="nouveau.modeset=0 rd.driver.blacklist=nouveau" --update-kernel=ALL
- 为了提高安全性,创建一个黑名单配置文件
1
2echo "blacklist nouveau" | sudo tee /etc/modprobe.d/blacklist-nouveau.conf
echo 'omit_drivers+=" nouveau "' | sudo tee /etc/dracut.conf.d/blacklist-nouveau.conf - 重新生成初始 RAM 文件系统:
1
2sudo dracut --regenerate-all --force
sudo depmod -a
- 为了提高安全性,创建一个黑名单配置文件
基本驱动程序验证
1
2
3yum install pciutils
sudo lspci | grep NVIDIA
nvidia-smiGUI 验证方法
1
nvidia-settings
参考链接
从坑中爬起:ESXi 8.0直通NVIDIA显卡的血泪经验
How To Install Nvidia Drivers on Rocky Linux 10