dolphinscheduler & seatunnel之http接口定时同步调度湖仓
背景与目标
我们之前曾评估使用过seatunnel做cdc入湖验证:seatunnel-cdc入湖实践,这些场景都是能直连数据库的场景,
业务需求中经常会出现无法直连数据库做cdc进行数据同步的场景,而这些场景就需要使用api进行数据对接,用海豚调度定时同步数据。
举个实际中的例子:
- ERP(SAP)的库存数据进行同步入湖仓做库存分析
同时,本次目标希望其他同事能依样画葫芦,在以后的对接http接口到湖仓的时候能够自行完成,而非每遇到一个对接需求,就需要通过代码方式进行对接。
准备工作
- seatunnel 2.3.10
首先,您需要在
${SEATUNNEL_HOME}/config/plugin_config文件中加入连接器名称,然后,执行命令来安装连接器,确认连接器在${SEATUNNEL_HOME}/connectors/目录下即可。
本例中我们会用到:connector-jdbc、connector-paimon
写入StarRocks也可以使用connector-starrocks,本例中的场景比较适合用connector-jdbc,所以使用connector-jdbc1
2
3
4
5
6# 配置连接器名称
--connectors-v2--
connector-jdbc
connector-starrocks
connector-paimon
--end--1
2# 安装连接器
sh bin/install-plugin.sh 2.3.10
seatunnel 任务
我们先至少保证能在本地完成seatunnel任务,再完成对海豚调度的对接
http to starRocks
example/http2starrocks1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102env {
parallelism = 1
job.mode = "BATCH"
}
source {
Http {
plugin_output = "stock"
url = "https://ip/http/prd/query_sap_stock"
method = "POST"
headers {
Authorization = "Basic XXX"
Content-Type = "application/json"
}
body = """{"IT_WERKS": [{"VALUE": "1080"}]}"""
format = "json"
content_field = "$.ET_RETURN.*"
schema {
fields {
MATNR = "string"
MAKTX = "string"
WERKS = "string"
NAME1 = "string"
LGORT = "string"
LGOBE = "string"
CHARG = "string"
MEINS = "string"
LABST = "double"
UMLME = "double"
INSME = "double"
EINME = "double"
SPEME = "double"
RETME = "double"
}
}
}
}
# 此转换操作主要用于字段重命名等用途
transform {
Sql {
plugin_input = "stock"
plugin_output = "stock-tf-out"
query = "select MATNR, MAKTX, WERKS,NAME1,LGORT,LGOBE,CHARG,MEINS,LABST,UMLME,INSME,EINME,SPEME,RETME from stock"
}
}
# 连接starRocks 进行数据分区覆写,本例适用starRocks建表,按照分区insert overwrite 覆写
sink {
jdbc {
plugin_input = "stock-tf-out"
url = "jdbc:mysql://XXX:9030/scm?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "lab"
password = "XXX"
compatible_mode="starrocks"
query = """insert overwrite ods_sap_stock PARTITION (WERKS='1080') (MATNR, MAKTX, WERKS,NAME1,LGORT,LGOBE,CHARG,MEINS,LABST,UMLME,INSME,EINME,SPEME,RETME) values(?,?,?,?,?,?,?,?,?,?,?,?,?,?)"""
}
}
# connector-starrocks进行对接 (未看到支持sql语句进行数据insert overwrite,本例子场景不适合),比较适合表数据全部删除重建场景
// sink {
// StarRocks {
// plugin_input = "stock-tf-out"
// nodeUrls = ["ip:8030"]
// base-url = "jdbc:mysql://ip:9030/"
// username = "lab"
// password = "XXX"
// database = "scm"
// table = "ods_sap_stock"
// batch_max_rows = 1000
// data_save_mode="DROP_DATA"
// starrocks.config = {
// format = "JSON"
// strip_outer_array = true
// }
// schema_save_mode = "RECREATE_SCHEMA"
// save_mode_create_template="""
// CREATE TABLE IF NOT EXISTS `scm`.`ods_sap_stock` (
// MATNR STRING COMMENT '物料',
// WERKS STRING COMMENT '工厂',
// LGORT STRING COMMENT '库存地点',
// MAKTX STRING COMMENT '物料描述',
// NAME1 STRING COMMENT '工厂名称',
// LGOBE STRING COMMENT '地点描述',
// CHARG STRING COMMENT '批次编号',
// MEINS STRING COMMENT '单位',
// LABST DOUBLE COMMENT '非限制使用库存',
// UMLME DOUBLE COMMENT '在途库存',
// INSME DOUBLE COMMENT '质检库存',
// EINME DOUBLE COMMENT '受限制使用的库存',
// SPEME DOUBLE COMMENT '已冻结的库存',
// RETME DOUBLE COMMENT '退货'
// ) ENGINE=OLAP
// PRIMARY KEY ( MATNR,WERKS,LGORT)
// COMMENT 'sap库存'
// DISTRIBUTED BY HASH (WERKS) PROPERTIES (
// "replication_num" = "1"
// )
// """
// }
// }http to paimon
example/http2paimon1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61env {
parallelism = 1
job.mode = "BATCH"
}
source {
Http {
plugin_output = "stock"
url = "https://ip/http/prd/query_sap_stock"
method = "POST"
headers {
Authorization = "Basic XXX"
Content-Type = "application/json"
}
body = """{"IT_WERKS": [{"VALUE": "1080"}]}"""
format = "json"
content_field = "$.ET_RETURN.*"
schema {
fields {
MATNR = "string"
MAKTX = "string"
WERKS = "string"
NAME1 = "string"
LGORT = "string"
LGOBE = "string"
CHARG = "string"
MEINS = "string"
LABST = "double"
UMLME = "double"
INSME = "double"
EINME = "double"
SPEME = "double"
RETME = "double"
}
}
}
}
# 此转换操作主要用于字段从命名等方便用途
transform {
Sql {
plugin_input = "stock"
plugin_output = "stock-tf-out"
query = "select MATNR, MAKTX, WERKS,NAME1,LGORT,LGOBE,CHARG,MEINS,LABST,UMLME,INSME,EINME,SPEME,RETME from stock"
}
}
# 连接paimon进行数据同步,paimon 暂时 未看到有支持 insert overwrite 分区覆写,此例仅作为参考,不适用本此例子需求
sink {
Paimon {
warehouse = "s3a://test/"
database = "sap"
table = "ods_sap_stock"
paimon.hadoop.conf = {
fs.s3a.access-key=XXX
fs.s3a.secret-key=XXX
fs.s3a.endpoint="http://minio:9000"
fs.s3a.path.style.access=true
fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider
}
}
}
dolphinscheduler 集成seatunnel
- 制作worker镜像打包镜像,推送到镜像仓库
1
2
3
4
5FROM dolphinscheduler.docker.scarf.sh/apache/dolphinscheduler-worker:3.2.2
RUN mkdir /opt/seatunnel
RUN mkdir /opt/seatunnel/apache-seatunnel-2.3.10
# 容器集成seatunnel
COPY apache-seatunnel-2.3.10/ /opt/seatunnel/apache-seatunnel-2.3.10/1
docker build --platform=linux/amd64 -t apache/dolphinscheduler-worker:3.2.2-seatunnel .
- 使用新镜像部署一个worker,此处修改
docker-compose.yaml,增加一个dolphinscheduler-worker-seatunnel节点1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22...
dolphinscheduler-worker-seatunnel:
image: xxx/dolphinscheduler-worker:3.2.2-seatunnel
profiles: ["all"]
env_file: .env
healthcheck:
test: [ "CMD", "curl", "http://localhost:1235/actuator/health" ]
interval: 30s
timeout: 5s
retries: 3
depends_on:
dolphinscheduler-zookeeper:
condition: service_healthy
volumes:
- ./dolphinscheduler-worker-seatunnel-data:/tmp/dolphinscheduler
- ./dolphinscheduler-logs:/opt/dolphinscheduler/logs
- ./dolphinscheduler-shared-local:/opt/soft
- ./dolphinscheduler-resource-local:/dolphinscheduler
networks:
dolphinscheduler:
ipv4_address: 172.15.0.18
... - dolphinscheduler配置seatunnel 分组及环境配置
安全中心-Worker分组管理,创建一个这个节点ip的分组,用于以后需要seatunnel的任务跑该分组
环境管理-创建环境,增加一个用于执行seatunnel的环境,同时需要绑定Worker分组为上一步创建的seatunnel分组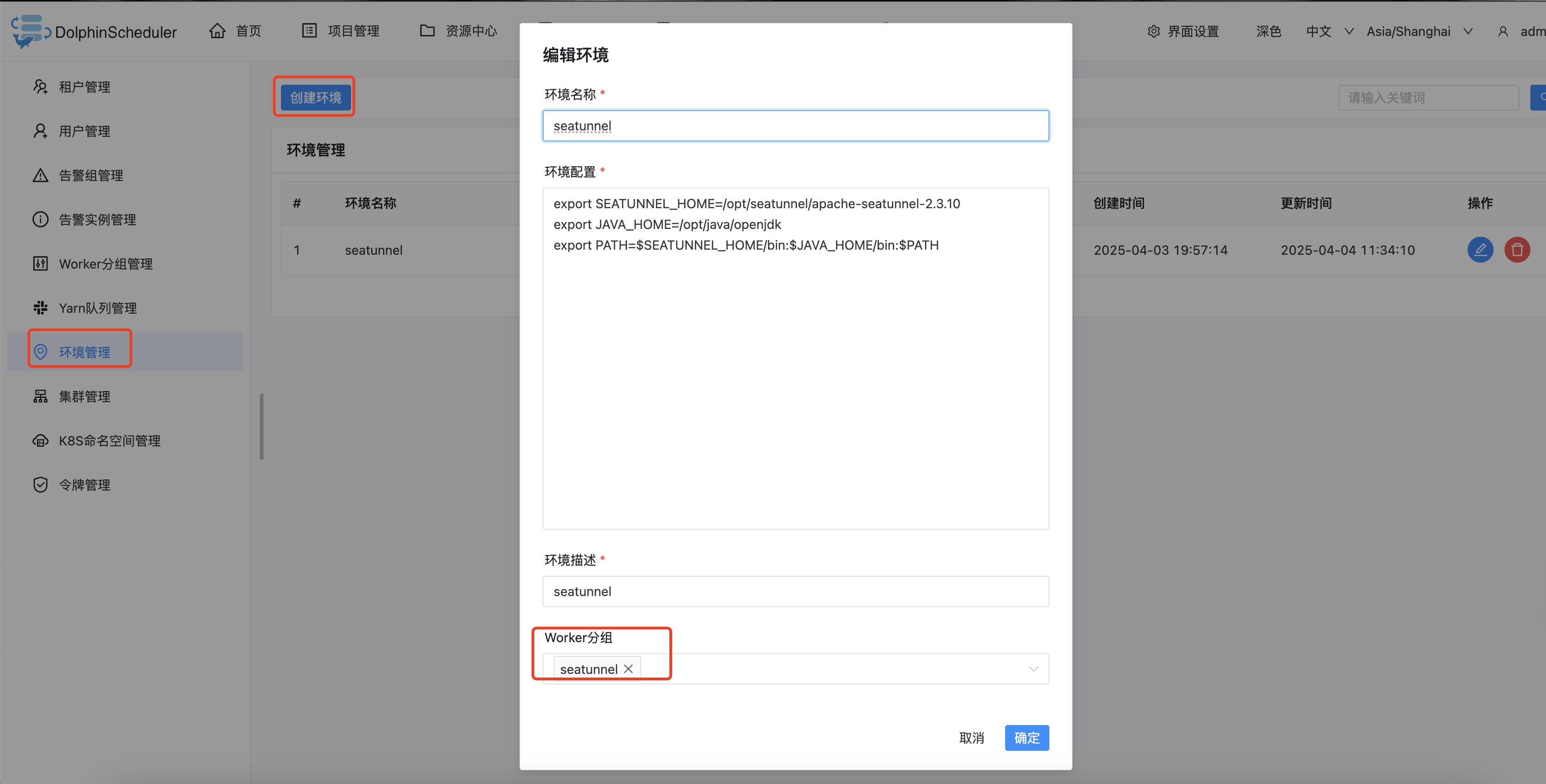
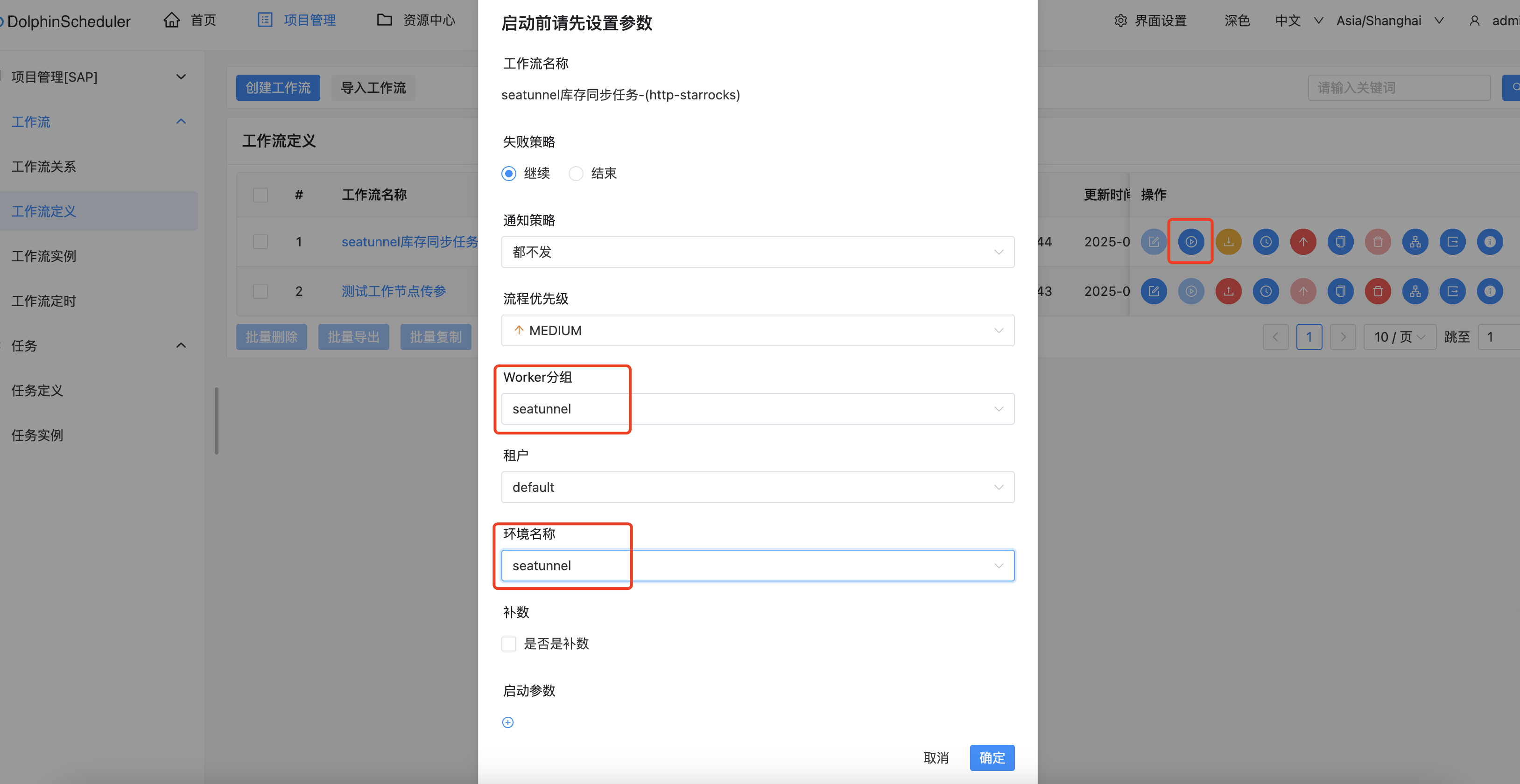
- 创建工作流定义,把上面的seatunnel任务配置填写上
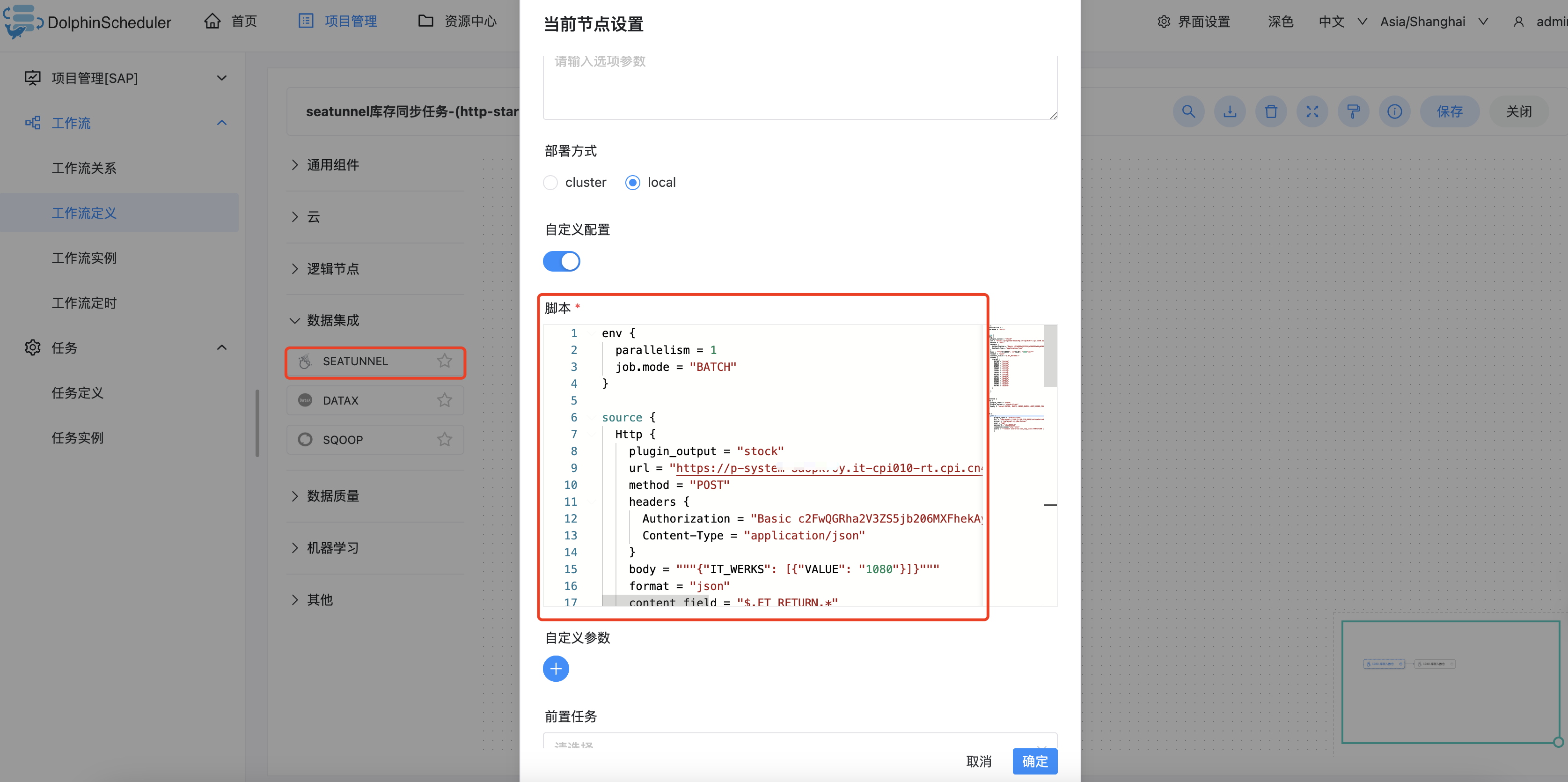
- 运行时候,选择seatunnel的worker分组和环境即可跑在这个集成了seatunnel的环境上