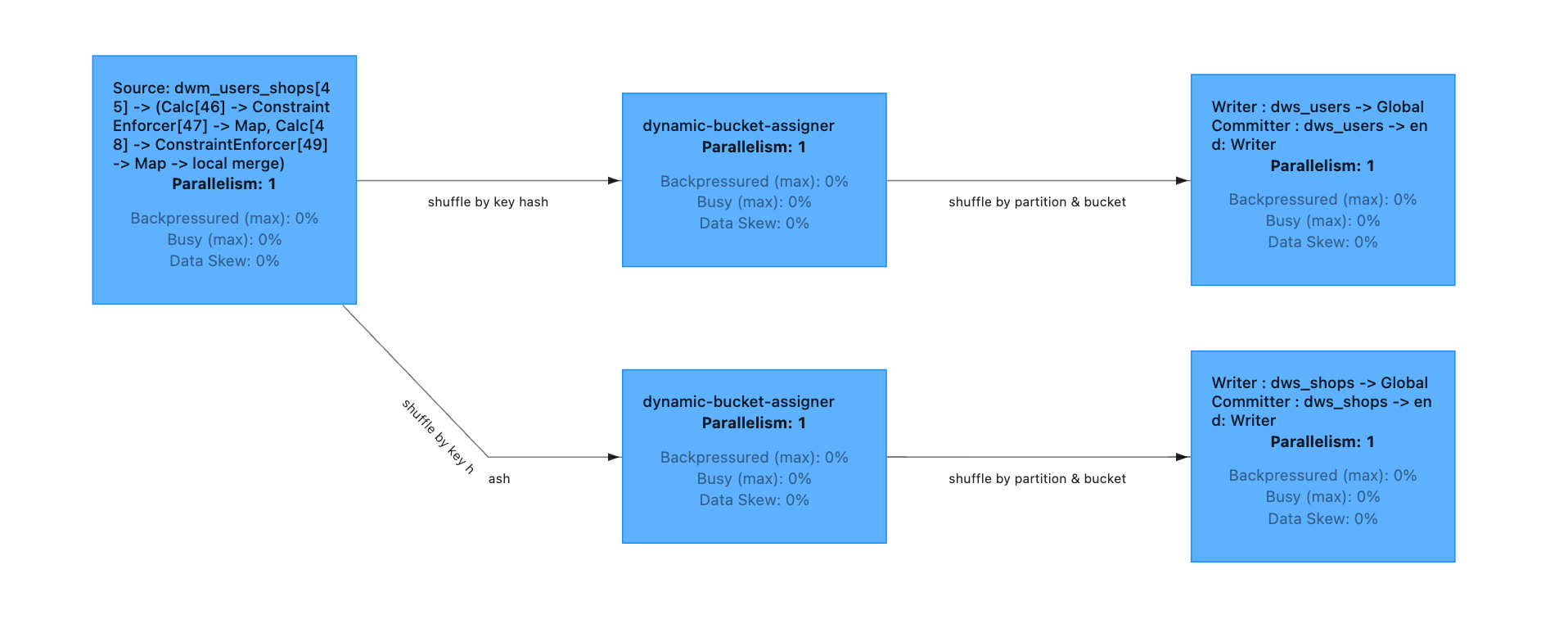
LLaMA-Factory + Qwen2.5-1.5B-Instruct再微调一次甄嬛
背景
大模型领域日新月异,模型微调早已无代码化,我认为大模型训练和微调的关键步骤仅剩:高质量的数据集准备。
之前微调过一次甄嬛 Mac M2之LLaMA3-8B微调(llama3-fine-tuning), 这次我想用 llama-factory + Qwen2.5-1.5B-Instruct完全无代码微调一次。
LLaMA-Factory
1 | ## 克隆项目 |
校验环境
1 | import torch |
执行webui
1 | llamafactory-cli webui |
执行完毕后,会自动打开webui
数据集
本次我们依然使用该数据集:Chat-嬛嬛数据集llama-factory 目前只支持Alpaca和Sharegpt两种格式的数据集。
- Alpaca 格式
适用于单轮任务,如问答、文本生成、摘要、翻译等。结构简洁,任务导向清晰,适合低成本的指令微调。1
2
3
4
5{
"instruction":"计算这些物品的总费用。",
"input":"输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output":"汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
} - ShareGPT 格式
适用于多轮对话、聊天机器人等任务。结构复杂,包含多轮对话上下文,适合高质量的对话生成和人机交互任务。1
2
3
4
5
6
7
8
9[{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
["今天会下雨吗?", "今天不会下雨,是个好天气。"],
["今天适合出去玩吗?", "非常适合,空气质量很好。"]
]
}]
打开 huanhuan.json 文件,可以看到它其实就是 Alpaca 格式的数据集,仅下载这一个文件即可。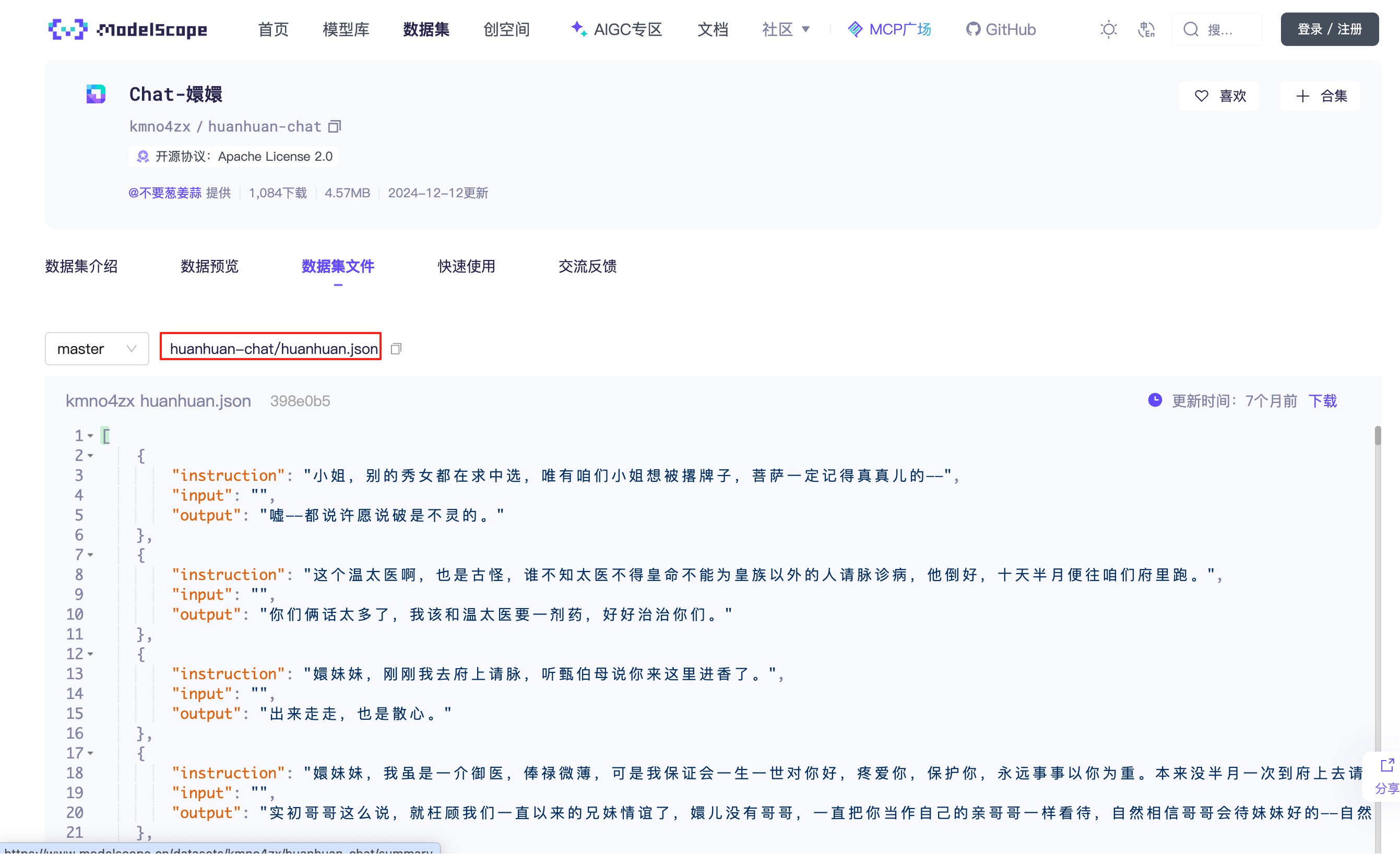
我们在 llama-factory 项目内的的data目录放置 huanhuan.json 文件,并且在 dataset_info.json 的配置文件添加一条 huanhuan.json 的json配置,这样,我们新添加的数据集才能被llama-factory注册识别到。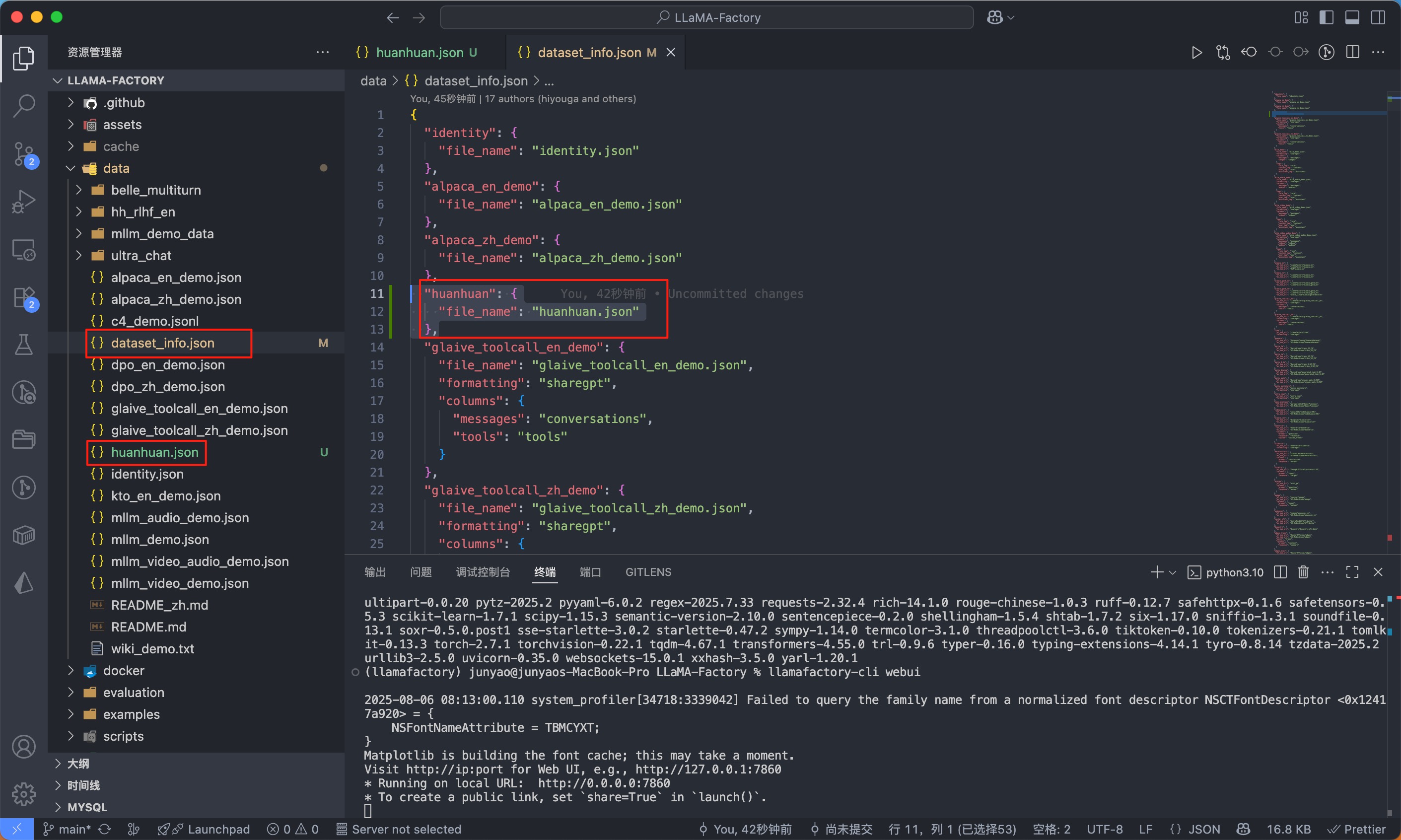
微调
首先是模型,我们选择此次需要微调的Qwen2.5-1.5B-Instruct。
- Instruct 版本(如 Qwen2.5-1.5B-Instruct) ✅
- 经过指令微调的模型
- 更适合直接对话和指令遵循
- 已经具备基本的对话能力
- 更适合用来进一步微调
微调方式使用默认的lora即可。
训练轮数可以选择1轮,会快一些(如果后面发现效果不理想,可以多训练几轮),我这里最终选择了3轮,因为我发现仅1轮效果不佳。计算类型默认截断长度设置小一点,为1024(默认是2048)。梯度累计设置为4。其他参数设置-预热步数是学习率预热采用的步数,通常设置范围在2-8之间,我们这里配置4。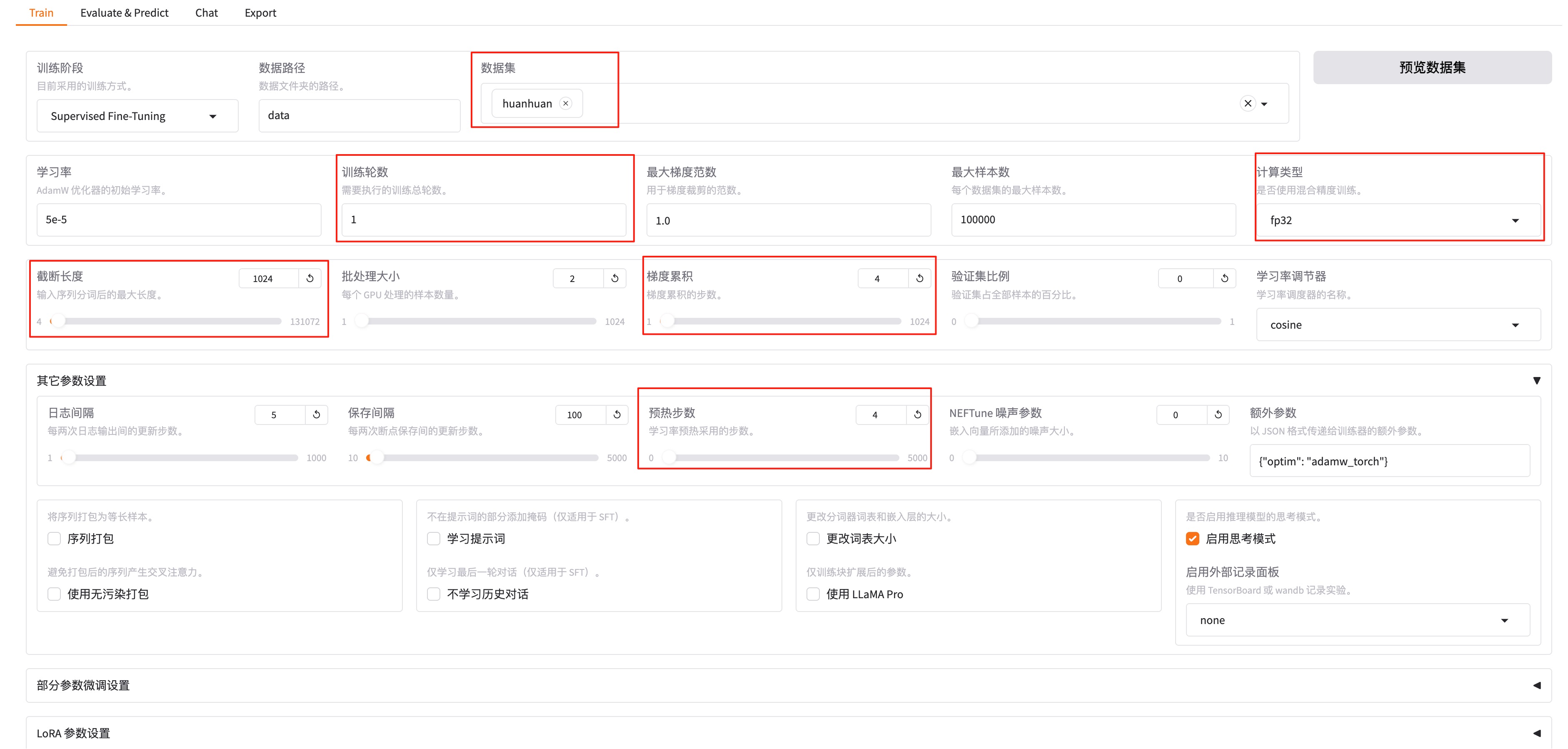
LoRA参数设置-lora秩越大(可以看作学习的广度),学习的东西越多,微调之后的效果可能会越好,但是也不是越大越好。太大的话容易造成过拟合(书呆子,照本宣科,不知变通),这里设置为8。LoRA参数设置-lora缩放系数(可以看作学习强度),越大效果可能会越好,对于一些用于复杂场景的数据集可以设置更大一些,简单场景的数据集可以稍微小一点。我这里设置256。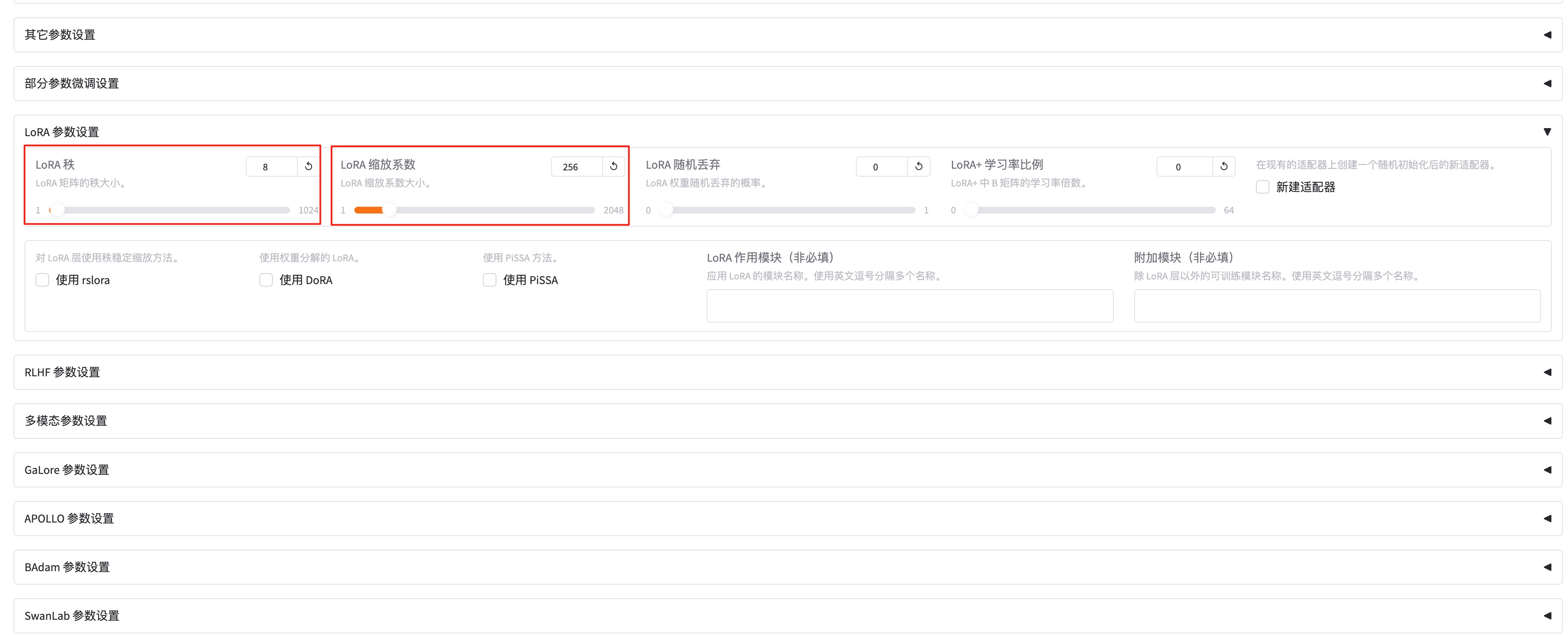
模型训练结束后,会显示:训练完毕。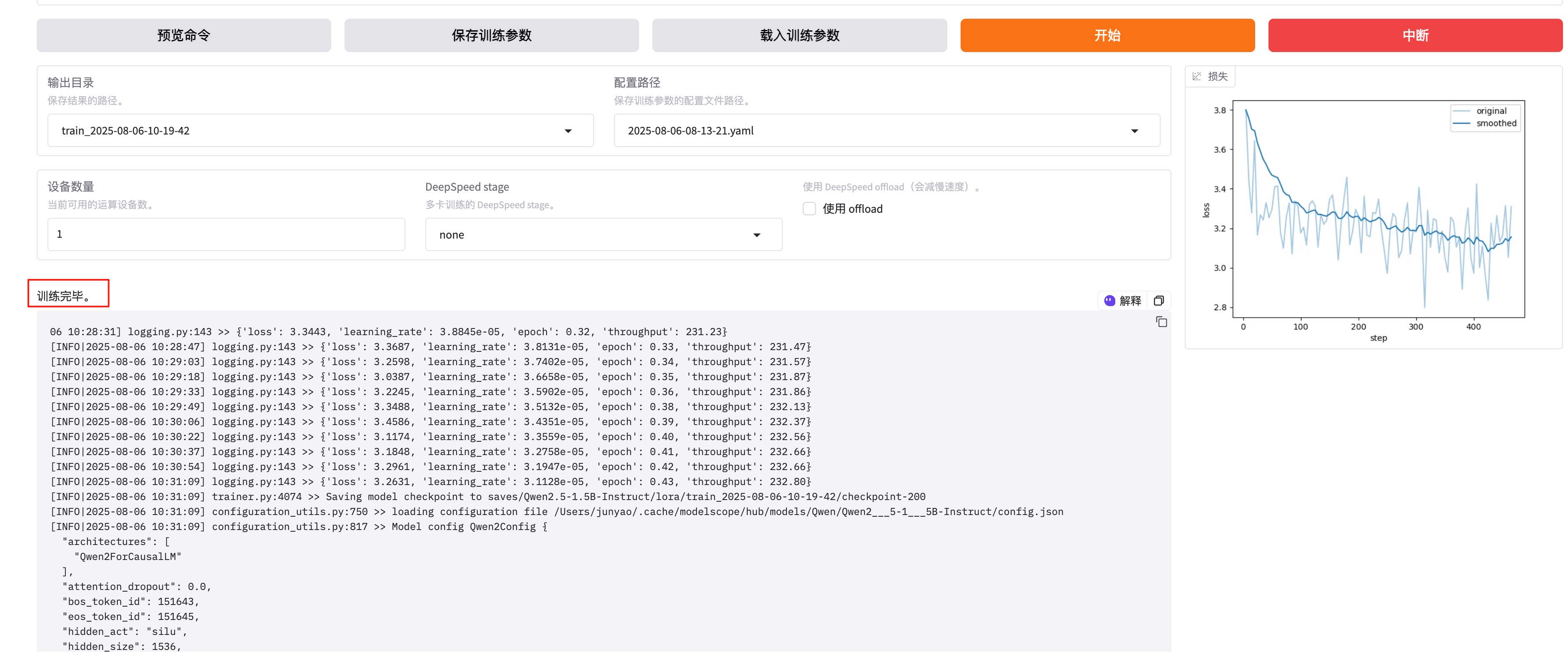
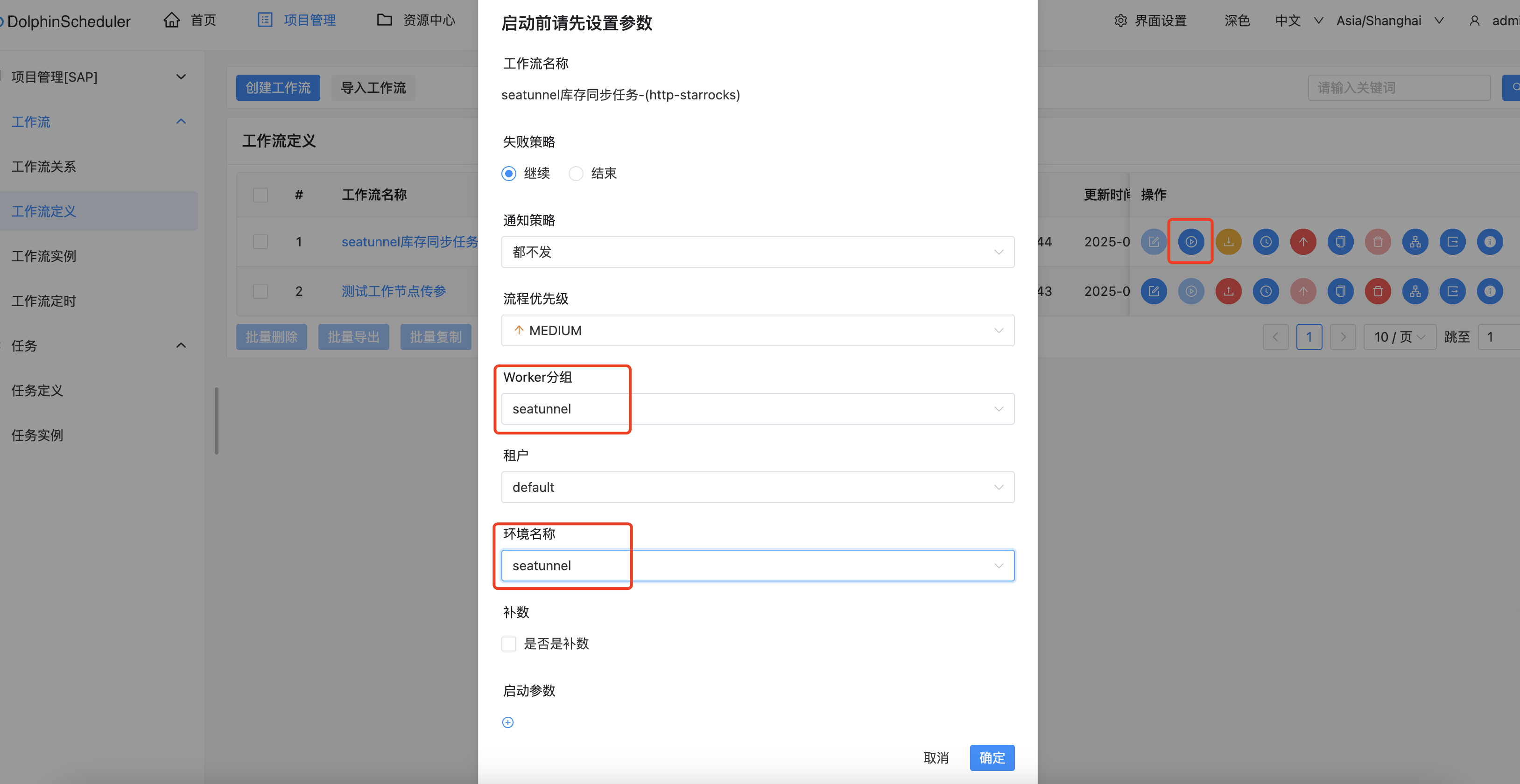
如果想重新微调,记得改一下下面红框中的两个值。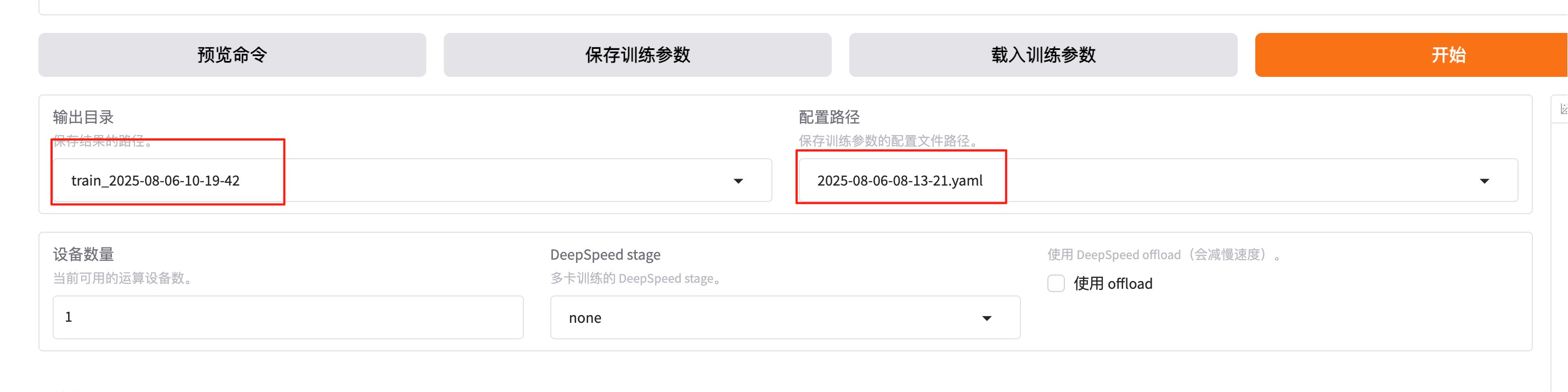
微调成功后,在检查点路径这里,下拉可以选择我们刚刚微调好的模型。把窗口切换到chat,点击加载模型。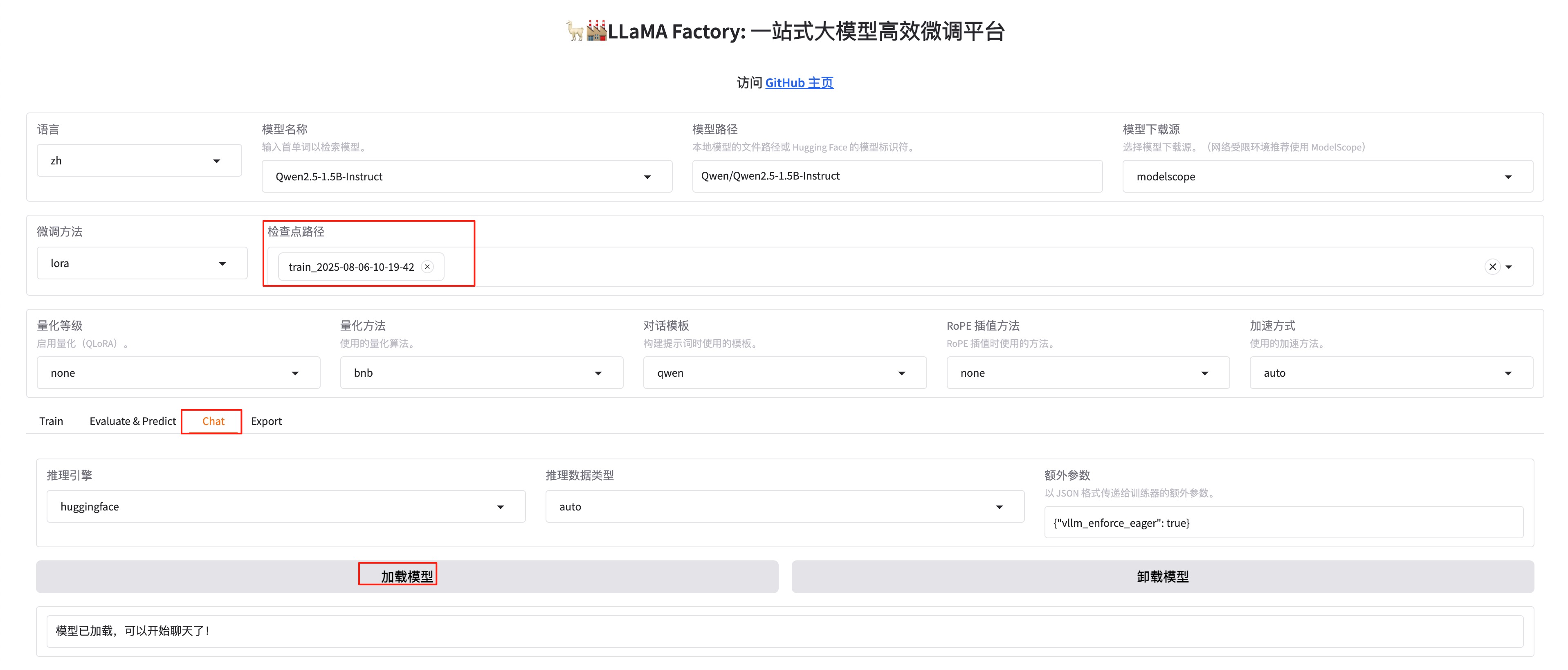
加载好之后就可以在输入框发送问题,测试微调模型的回复效果了。如果想切换回微调之前的模型,只需要把检查点路径置空。然后在chat这里卸载模型,再加载模型即可。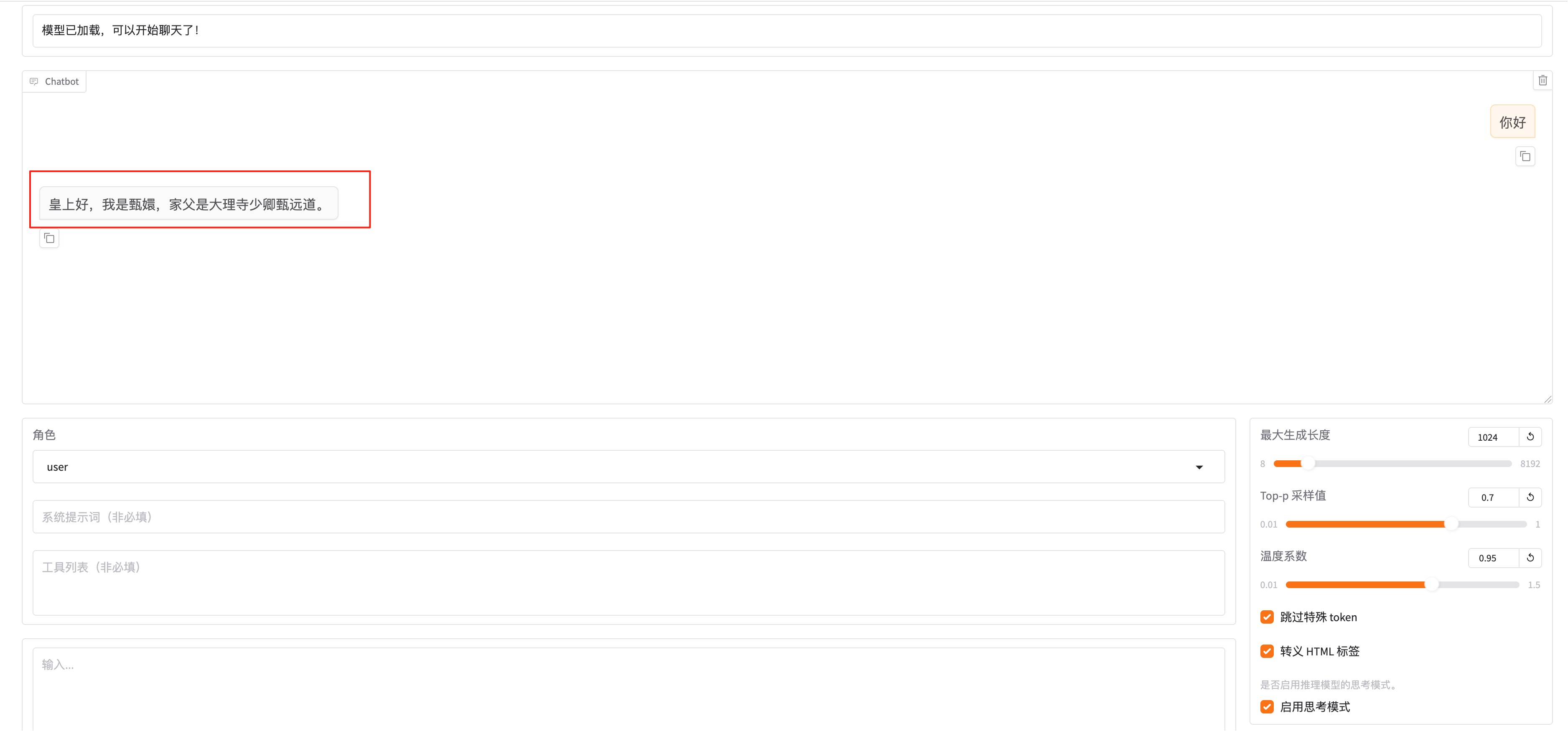
导出模型与使用
切换到export,填写导出目录models/huanhuan
大语言模型的参数通常以高精度浮点数(如32位浮点数,FP32)存储,这导致模型推理需要大量计算资源。量化技术通过将高精度数据类型存储的参数转换为低精度数据类型(如8位整数,INT8)存储,可以在不改变模型参数量和架构的前提下加速推理过程。这种方法使得模型的部署更加经济高效,也更具可行性。
量化前需要先将模型导出后再量化。修改模型路径为导出后的模型路径,导出量化等级一般选择 8 或 4,太低模型会答非所问。
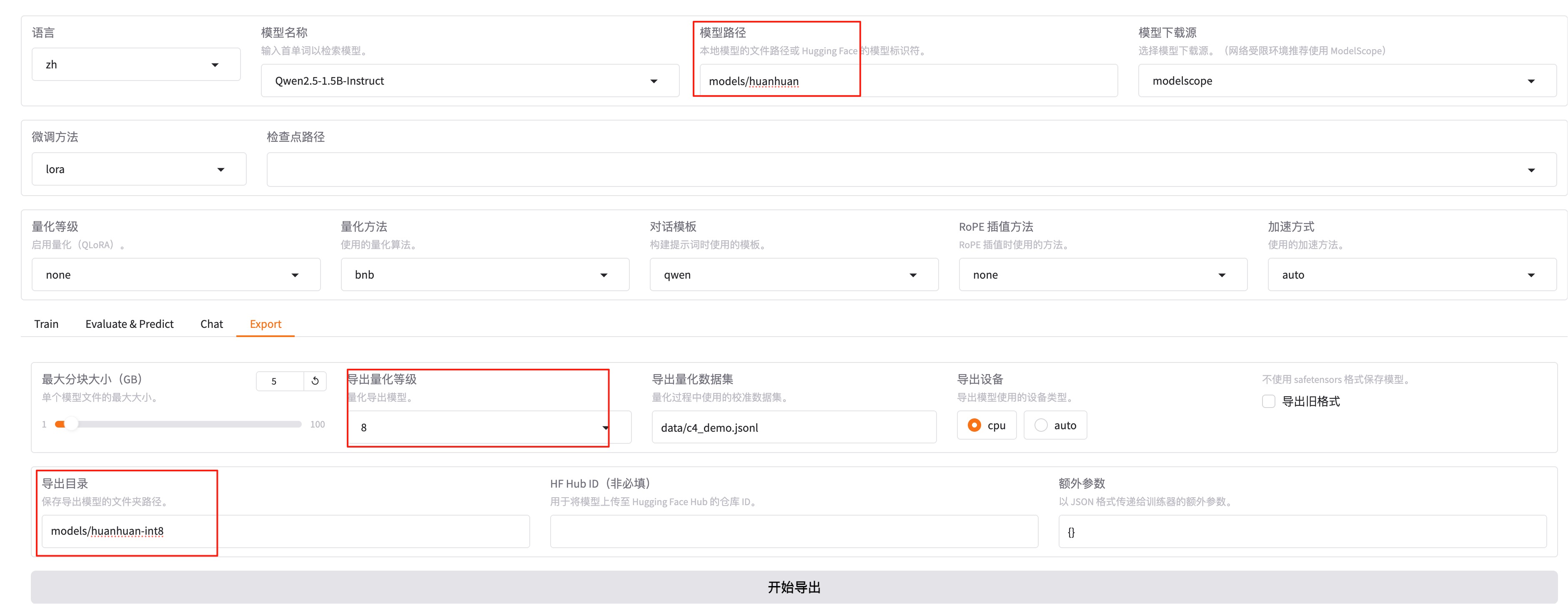
- 导入ollama
出现ollama和在llama-factory的chat回答效果不一致,请查看底部
相关链接1
2
3ollama create Qwen2.5-1.5B-huanhuan -f Modefile
ollama list
ollama run Qwen2.5-1.5B-huanhuan:latest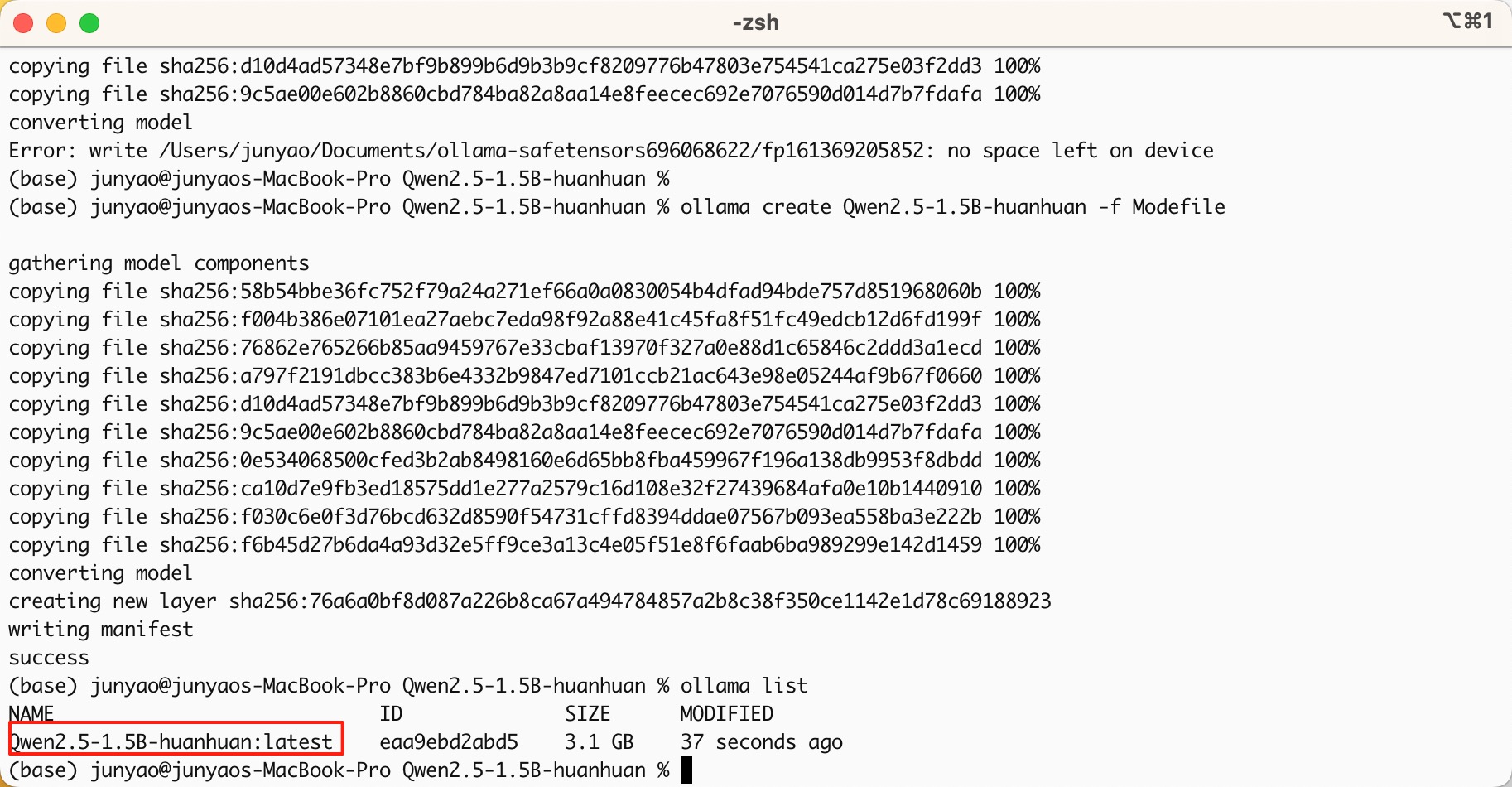
- vllm部署使用
出现vllm和在llama-factory的chat回答效果不一致,请查看底部
相关链接- 启动
1
2
3
4
5vllm serve /root/autodl-tmp/LLaMA-Factory/models/huanhuan/Qwen2.5-1.5B-huanhuan \
--port 8000 \
--host 0.0.0.0 \
--gpu-memory-utilization 0.8 \
--served-model-name huanhuan - 发送请求
1
2
3
4
5
6
7
8curl --location 'http://192.168.103.43:8000/v1/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "huanhuan",
"prompt": "你是谁",
"max_tokens": 50,
"temperature": 0.7
}' - 效果
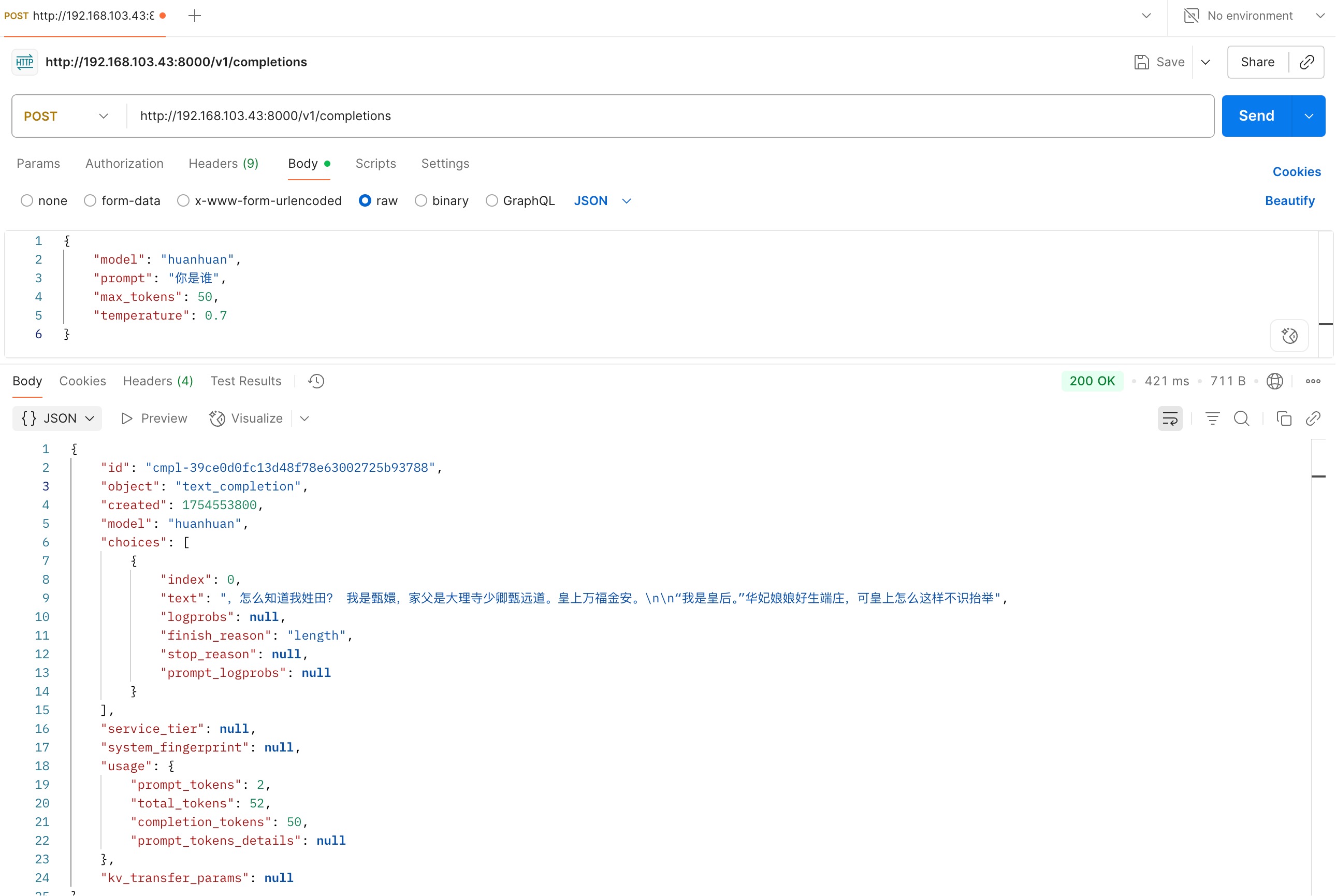
- 启动