LangChain DeepAgents Skills + Qwen3.5-35B-A3B 构建数据分析智能体
一、LangChain DeepAgents Skills
本文将基于 LangChain DeepAgents Skills + Qwen3.5-35B-A3B 构建一个数据库查询智能体,并实现数据方面的问答、分析。在实验开始前先了解下 LangChain DeepAgents 下的 Skills 的用法。
Skills 是一种轻量级的开放格式,通过 Skills 可以将专业知识打包成可发现的功能。在本专栏的前面文章中,给大家介绍及实验了 Qwen Code Skills ,在 LangChainDeepAgents 框架中是相同的概念,都是一种渐进式的知识获取策略,甚至 Skills 的定义方式都是相同的。
在 LangChainDeepAgents 框架中,Skills 同样是一个包含SKILL.md文件和其他脚本、模板和参考内容构成的技能包,结构如下所示:
1 | my-skill/ |
SKILL.md 示例模版:
其中 name 和 description 不可为空!
1 | --- |
在 SKILL.md 中定义专业的知识、流程或思路,同时也可以在 scripts 下增加一些工具脚本,以扩充模型的能力,这些信息不会一次性全部加载到主会话中,只有用户的问题和某个 Skills 的 description 相关,才会渐进式的加载 SKILL.md 中的内容,因此对于 description 不可写的太片面,最好能充分体现出 terrestrial 该 Skills 所支持的能力。
DeepAgents Skills 使用说明
在 DeepAgents 中已经封装好了对 Skills发现、激活、执行的过程,因此我们只需着重关注 Skills 的定义,然后将 Skills 所在目录提供给 DeepAgents 即可,例如:
1 | agent = create_deep_agent( |
二、Qwen3.5-35B-A3B 模型
Qwen3.5 系列是阿里最新迭代大模型,在推理、编程、智能体能力与多模态理解等全方位基准评估中表现优异。
图片
本文使用 modelscope 上提供的免费 API 调用 Qwen3.5-35B-A3B 模型,使用方式及获取 Api Key文档如下:
https://modelscope.cn/docs/model-service/API-Inference/intro
模型调用示例:
1 | from openai import OpenAI |
LangChain 调用示例:
1 | import os |
三、构建自定义 Skills 数据分析智能体
依赖所使用的主要依赖版本如:
1 | openai==2.14.0 |
3.1 实验数据说明
实验数据采用 COVID-19 测试案例,包括:美国 2021-01-28 号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示:
1 | date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例) |
下载地址如下:
https://github.com/BIXUECHAO/covid-19-tes-data/blob/main/us-covid19-counties.csv
创建数据表,并导入上述数据:
1 | CREATE TABLE `us_covid19_counties` ( |
3.2 构建 Skill
在项目的目录下创建 skills/db 技能包,整体结构如下所示:
1 | skills/db/ |
图片
其中 scripts/run_sql.py 用于动态查询数据库中的数据,接收SQL参数,通过 bash 指令运行。
3.2.1 编写 SKILL.md
主要描述出技能的能力,这里放入了表结构,如果表特别多的情况下,也可以写一个 scripts 脚本动态获取。另外为了更好的让大模型处理,最好提供调用脚本的指令示例。
1 | --- |
数据样例
1 | date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例) |
指令
运行辅助脚本:
1 | # 查询数据 |
注意python需要使用绝对路径!
示例
- 统计每个州的累计确诊病例注意 Python 路径修改为你电脑的实际路径,如果配置了环境变量可直接改为 python -u scripts/run_sql.py –sql “{sql}”:
1
E:\anaconda\conda\envs\openai\python.exe -u scripts/run_sql.py --sql "SELECT state, COUNT(*) AS total_cases FROM us_covid19_counties GROUP BY state ORDER BY total_cases DESC"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
### 3.2.2 编写 scripts 脚本
编写 skills/db/scripts/run_sql.py 脚本,执行数据查询动作:
```python
import json
import argparse
import pymysql
def get_conn():
return pymysql.connect(
host="127.0.0.1",
port=3306,
database="test3",
user="root",
password="root",
autocommit=True
)
def query(sql):
conn = get_conn()
cursor = conn.cursor()
cursor.execute(sql)
columns = [column[0] for column in cursor.description]
res = list()
for row in cursor.fetchall():
res.append(dict(zip(columns, row)))
cursor.close()
conn.close()
return res
def run_sql(sql: str):
"""执行MySQL SQL语句查询数据,一次仅能执行一句SQL!"""
try:
if not sql:
print("请传递需要查询的SQL!")
return
fetch = query(sql)
print(f"数据库查询结果: \n{fetch}")
except Exception as e:
print(f"执行SQL错误:{str(e)} ,请修正后重新发起。")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Run a SQL query.")
parser.add_argument('--sql', type=str, required=True, help='SQL query to execute')
args = parser.parse_args()
sql = args.sql
run_sql(sql)
3.3 DeepAgents 结合 Skills 构建智能体
3.3.1 智能体搭建
1 | import os |
其中 DeepAgents 中的 read_file工具,目前版本下暂不支持Windows绝对地址,可通过 system_prompt 纠正模型使用。
3.3.2 效果测试1
输入问题:你有哪些技能?
执行过程:
1 | 请输入: 你有哪些技能? |
最终输出结果:
根据我的配置,我拥有以下技能:
🛠️ 基础工具能力
• 任务管理 (write_todos) - 创建和管理结构化任务列表
• 文件操作 (ls, read_file, write_file, edit_file) - 浏览、读取、写入和编辑文件
• 文件搜索 (glob, grep) - 按模式查找文件和搜索文本内容
• 命令执行 (execute) - 在沙箱环境中运行 shell 命令
• 子代理 (task) - 启动独立子代理处理复杂任务
📊 专业技能
- db - COVID-19 数据查询
• 功能:查询美国 2021-01-28 号各县 (county) 的新冠疫情数据
• 数据内容:确诊病例数、死亡病例数
• 覆盖范围:美国各县级别数据
如果你需要我帮助完成某项任务,比如查询疫情数据、处理文件、执行代码或研究复杂问题,随时告诉我!
3.3.3 效果测试2
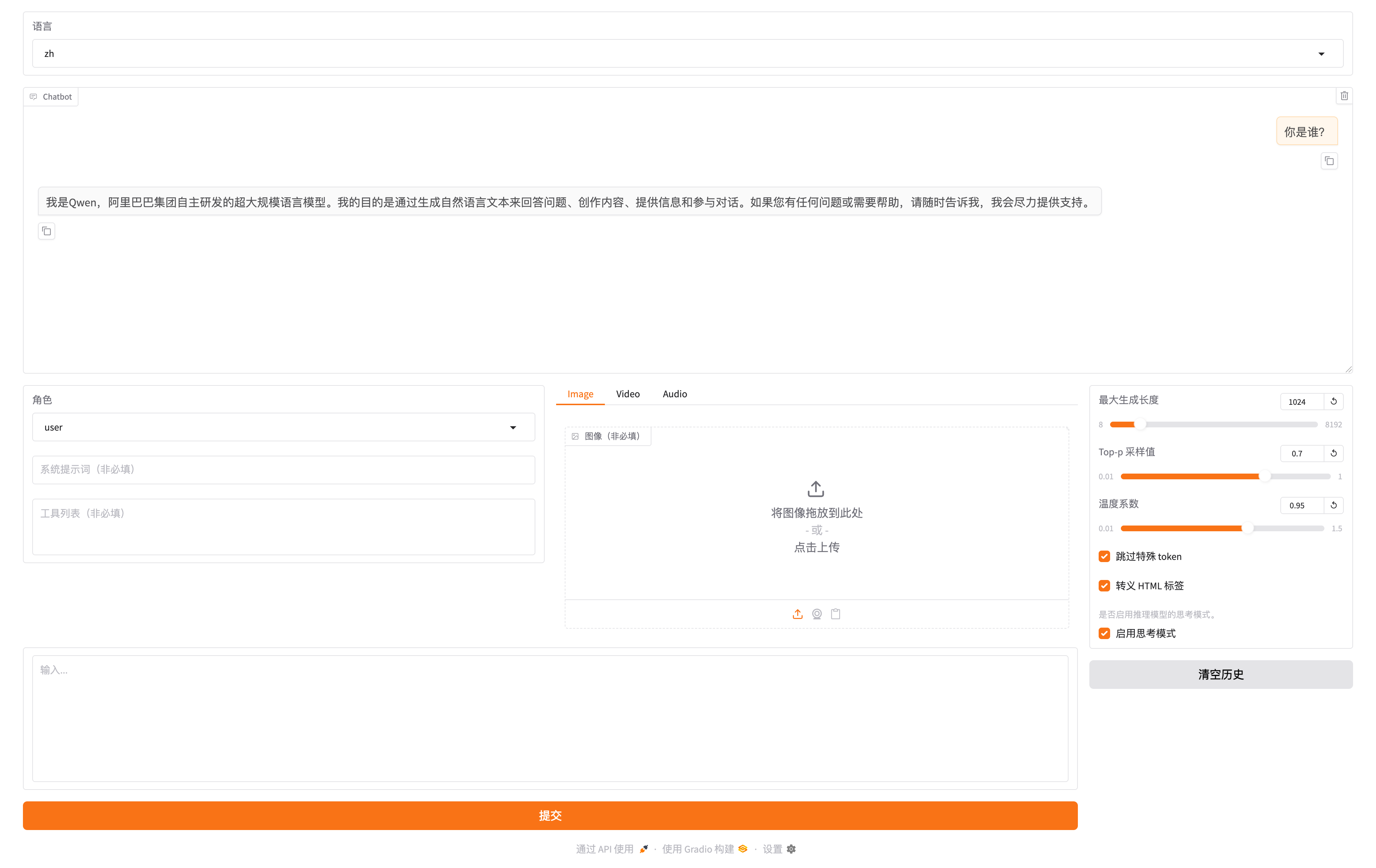
输入问题:确诊人数Top10的县是哪几个?
执行过程:
请输入: 确诊人数Top10的县是哪几个?
>>>>>>>>>> Call Tools <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
Tool: read_file , Args: {'file_path': '/pyProject/deepagents-demo/skills/db/SKILL.md'}
>>>>>>>>>>>>>>>>>>>> Tools Output <<<<<<<<<<<<<<<<<<<<
Tool: read_file, Output:
1 ---
2 name: db
3 description: COVID-19数据查询, 包括:美国 2021-01-28 号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例
4 ---
5
6 # 数据查询
7
8 ## 数据表结构
9 ```sql
10 CREATE TABLE `us_covid19_counties` (
11 `date` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '日期',
12 `county` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '县',
13 `state` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '州',
14 `fips` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '县编码code',
15 `cases` int DEFAULT NULL COMMENT '累计确诊病例',
16 `deaths` int DEFAULT NULL COMMENT '累计死亡病例'
17 ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='COVID-19 案例';
18 ```
19
20 ## 数据样例
21 ```data
22 date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)
23 2021-01-28,Pike,Alabama,01109,2704,35
24 2021-01-28,Randolph,Alabama,01111,1505,37
25 2021-01-28,Russell,Alabama,01113,3675,16
26 2021-01-28,Shelby,Alabama,01117,19878,141
27 2021-01-28,St. Clair,Alabama,01115,8047,147
28 2021-01-28,Sumter,Alabama,01119,925,28
29 2021-01-28,Talladega,Alabama,01121,6711,114
30 2021-01-28,Tallapoosa,Alabama,01123,3258,112
31 2021-01-28,Tuscaloosa,Alabama,01125,22083,283
32 2021-01-28,Walker,Alabama,01127,6105,185
33 2021-01-28,Washington,Alabama,01129,1454,27
34 ```
35
36 ## 指令
37 运行辅助脚本:
38 ```bash
39 # 查询数据
40 E:\anaconda\conda\envs\openai\python.exe -u scripts/run_sql.py --sql "{sql}"
41 ```
42 注意python需要使用绝对路径!
43
44 ## 示例
45 - 统计每个州的累计确诊病例
46 ```bash
47 E:\anaconda\conda\envs\openai\python.exe -u scripts/run_sql.py --sql "SELECT state, COUNT(*) AS total_cases FROM us_covid19_counties GROUP BY state ORDER BY total_cases DESC"
48 ```
>>>>>>>>>> AIMessage <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
我来查询确诊人数 Top10 的县。
>>>>>>>>>> Call Tools <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
Tool: execute , Args: {'command': 'E:\\anaconda\\conda\\envs\\openai\\python.exe -u /pyProject/deepagents-demo/skills/db/scripts/run_sql.py --sql "SELECT county, state, cases FROM us_covid19_counties WHERE date=\'2021-01-28\' ORDER BY cases DESC LIMIT 10"'}
>>>>>>>>>>>>>>>>>>>> Tools Output <<<<<<<<<<<<<<<<<<<<
Tool: execute, Output:
数据库查询结果:
[{'county': 'Los Angeles', 'state': 'California', 'cases': 1098363}, {'county': 'New York City', 'state': 'New York', 'cases': 591160}, {'county': 'Maricopa', 'state': 'Arizona', 'cases': 465009}, {'county': 'Cook', 'state': 'Illinois', 'cases': 450116}, {'county': 'Miami-Dade', 'state': 'Florida', 'cases': 366126}, {'county': 'Harris', 'state': 'Texas', 'cases': 308902}, {'county': 'San Bernardino', 'state': 'California', 'cases': 271189}, {'county': 'Riverside', 'state': 'California', 'cases': 270105}, {'county': 'Dallas', 'state': 'Texas', 'cases': 253684}, {'county': 'Orange', 'state': 'California', 'cases': 241648}]
[Command succeeded with exit code 0]
>>>>>>>>>> AIMessage <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
根据 2021 年 1 月 28 日的数据,**美国 COVID-19 累计确诊病例数 Top10 的县**如下:
| 排名 | 县 (County) | 州 (State) | 累计确诊病例 |
|:---:|------------|-----------|:---:|
| 1 | Los Angeles | California | 1,098,363 |
| 2 | New York City | New York | 591,160 |
| 3 | Maricopa | Arizona | 465,009 |
| 4 | Cook | Illinois | 450,116 |
| 5 | Miami-Dade | Florida | 366,126 |
| 6 | Harris | Texas | 308,902 |
| 7 | San Bernardino | California | 271,189 |
| 8 | Riverside | California | 270,105 |
| 9 | Dallas | Texas | 253,684 |
| 10 | Orange | California | 241,648 |
**观察:**
- 🏆 **洛杉矶县 (Los Angeles)** 确诊数遥遥领先,超过 109 万例
- 📍 **加州** 表现突出,Top10 中占据 4 席
- 📍 **德州** 有 2 个县进入 Top10
最终输出结果:
根据 2021 年 1 月 28 日的数据,美国 COVID-19 累计确诊病例数 Top10 的县如下:
排名
县 (County)
州 (State)
累计确诊病例
1
Los Angeles
California
1,098,363
2
New York City
New York
591,160
3
Maricopa
Arizona
465,009
4
Cook
Illinois
450,116
5
Miami-Dade
Florida
366,126
6
Harris
Texas
308,902
7
San Bernardino
California
271,189
8
Riverside
California
270,105
9
Dallas
Texas
253,684
10
Orange
California
241,648
观察:
• 🏆 洛杉矶县 (Los Angeles) 确诊数遥遥领先,超过 109 万例
• 📍 加州 表现突出,Top10 中占据 4 席
• 📍 德州 有 2 个县进入 Top10