LLaMA-Factory-行业垂直大模型微调训练·基础环境
硬件环境
首先按照 nvidia驱动安装 装下驱动
1 | nvidia-smi |
环境准备
- 安装依赖
1
2
3
4
5
6
7
8
9
10# 克隆项目
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 创建环境
conda create -n llamafactory python=3.10
# 激活环境
conda activate llamafactory
# 安装依赖
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
pip install -e ".[torch,metrics]" --no-build-isolation -i https://mirrors.aliyun.com/pypi/simple如果出现环境冲突,请尝试使用 pip install –no-deps -e . 解决
- 校验环境
1
2
3
4import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__1
2
3
4
5
6
7>>> import torch
>>> torch.cuda.current_device()
0
>>> torch.cuda.get_device_name(0)
'NVIDIA GeForce RTX 4090'
>>> torch.__version__
'2.8.0+cu128'1
2# 对本库的基础安装做一下校验,输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
llamafactory-cli train -h llamafactory-cli常见命令动作参数 功能说明 version显示版本信息 train命令行版本训练 chat命令行版本推理聊天 export模型合并和导出(如转换为Hugging Face/ONNX格式) api启动API服务器,提供HTTP接口调用 eval使用标准数据集(如MMLU)评测模型性能 webchat启动纯推理的Web聊天页面(简易前端) webui启动LlamaBoard多功能前端(含训练、预测、聊天、模型合并等可视化子页面) 另外两个关键参数解释如下,后续的基本所有环节都会继续使用这两个参数
参数名称 参数说明 model_name_or_path 参数的名称(huggingface或者modelscope上的标准定义,如 Qwen/Qwen2.5-1.5B-Instruct),或者是本地下载的绝对路径,如/root/autodl-tmp/LLaMA-Factory/models/Qwen/Qwen2.5-1.5B-Instructtemplate 模型问答时所使用的prompt模板,不同模型不同,请参考 LLaMA-Factory Supported Models 获取不同模型的模板定义,否则会回答结果会很奇怪或导致重复生成等现象的出现。chat版本的模型基本都需要指定,比如 Qwen/Qwen2.5-1.5B-Instruct的template就是qwen- 示例:下面四行命令分别是 启动webui 和对Llama3-8B-Instruct模型进行 LoRA 微调、推理、合并。
1
2
3
4
5CUDA_VISIBLE_DEVICES=0 USE_MODELSCOPE_HUB=1 llamafactory-cli webui
CUDA_VISIBLE_DEVICES=0 USE_MODELSCOPE_HUB=1 llamafactory-cli webui > runlog.log &
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
下载模型
我们自己手动下载并指定路径。
1 | pip install modelscope |
原始模型推理
transformers 原始模型直接推理
为qwen创建一个推理测试python脚本
1 | mkdir demo |
python generated_text.py
1 | import transformers |
输出:
1 | 我是来自阿里云的大规模语言模型,我叫通义千问。 |
llamafactory-cli 原始模型直接推理
touch examples/inference/qwen2.5.yaml
1 | model_name_or_path: /root/autodl-tmp/LLaMA-Factory/models/Qwen/Qwen2.5-1.5B-Instruct |
这样就可以通过如下命令启动:
- 终端推理:
llamafactory-cli chat examples/inference/qwen2.5.yaml1
2
3
4
5[INFO|2025-08-08 15:48:45] llamafactory.model.loader:143 >> all params: 1,543,714,304
Welcome to the CLI application, use `clear` to remove the history, use `exit` to exit the application.
User: 你是谁?
Assistant: 我是Qwen,由阿里云开发的语言模型。我能够回答问题、创作文字,还能表达观点、撰写代码。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。
User: - web推理:
llamafactory-cli webchat examples/inference/qwen2.5.yaml
效果如图,可通过http://localhost:7860/进行访问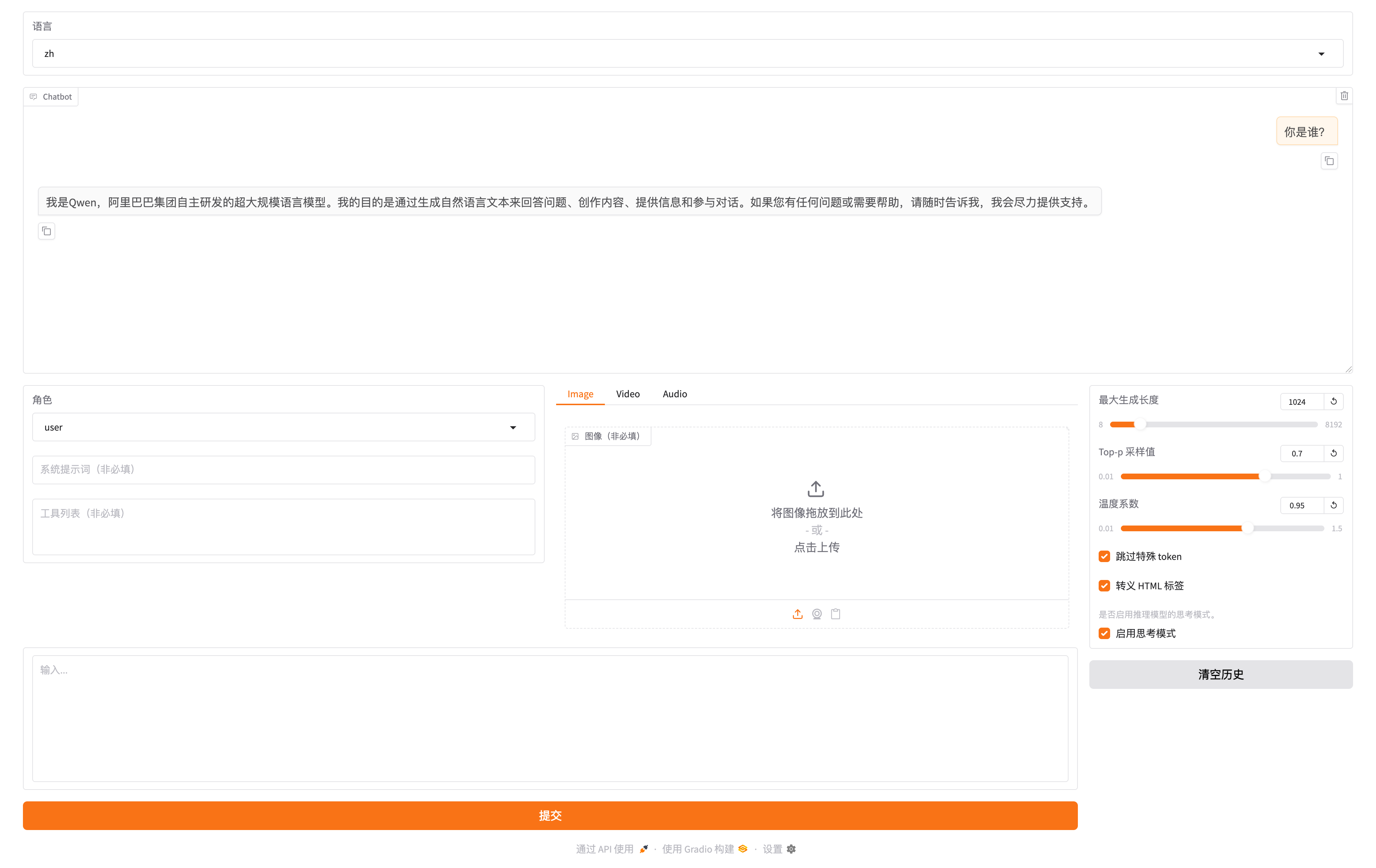
注意:这里的localhost:7860指的是程序启动机器自身的7860端口,云上的用户可能无法通过本地的笔记本电脑直接访问,需要找云厂商获取域名和端口号的一些配置关系进行配置
比如阿里云用户需要做一下如下环境变量的配置才能正常运行gradio,然后再通过阿里云给的域名映射访问1
export GRADIO_ROOT_PATH=/${JUPYTER_NAME}/proxy/7860/
构建自定义数据集
- 自带的identity.json数据集
系统自带的identity.json数据集,用于对模型自我介绍,示例:
data/identity.json1
2
3
4
5
6
7
8
9
10
11
12[
{
"instruction": "你好",
"input": "",
"output": "您好,我是 {{name}},一个由 {{author}} 开发的 AI 助手,很高兴认识您。请问我能为您做些什么?"
},
{
"instruction": "你好",
"input": "",
"output": "您好,我是 {{name}},一个由 {{author}} 打造的人工智能助手,请问有什么可以帮助您的吗?"
},
]1
2
3
4cd LLaMA-Factory
其中的NAME 和 AUTHOR ,替换成我们需要的内容
sed -i 's/{{name}}/达优AI助手/g' data/identity.json
sed -i 's/{{author}}/达科为/g' data/identity.json - 企业自己的数据集
dayou.json需要将该数据集注册到1
2
3
4
5
6
7
8[
{
"instruction": "低内毒素胰酶消化液的推荐储存条件是什么,这些条件如何确保其稳定性和活性?",
"input": "",
"output": "低内毒素胰酶消化液的储存条件对其稳定性和活性至关重要。以下是推荐的储存条件及其如何确保稳定性和活性的详细解释:\n\n## 🧪 推荐储存条件\n\n1. **温度:**\n * **长期储存: -20°C 或更低(如 -80°C)。** 这是最核心的条件。\n * **短期储存(几天内使用): 2-8°C (冰箱冷藏)。** 仅适用于已解冻并计划在极短时间内(通常不超过1周)用完的 aliquot(分装样品)。**不推荐**将未开封的浓缩液长期存放在冷藏温度。\n\n2. **分装:**\n * **强烈建议将大瓶装的胰酶消化液分装成小体积(如 0.5 mL, 1 mL, 5 mL 等)的无菌、低蛋白吸附的离心管或冻存管中。** 分装体积应根据单次实验用量来定,避免反复冻融。\n\n3. **容器:**\n * 使用**无菌、低蛋白吸附、低内毒素**的容器。推荐使用**高质量聚丙烯 (PP)** 材质的离心管或冻存管。避免使用可能吸附蛋白或释放塑化剂(如 DEHP)的聚苯乙烯 (PS) 管或低质量塑料管。玻璃容器也可,但需确保无菌且不易碎。\n\n4. **避光:**\n * 储存于**避光**环境中。虽然胰酶对光不特别敏感,但避光储存可防止任何潜在的光氧化反应,并提供额外的保护。\n\n5. **密封:**\n * 确保容器**密封良好**,防止水分蒸发(导致浓度变化)、空气进入(导致氧化或污染)以及微生物污染。\n\n## 📊 这些条件如何确保稳定性和活性?\n\n1. **低温 (-20°C 或更低):**\n * **抑制酶活性:** 胰蛋白酶等蛋白酶在低温下其催化活性被极大抑制。这**显著减缓了胰酶分子的自水解(自我降解)**。自水解是胰酶失活的主要途径之一,即使在溶液中也会缓慢发生。低温将这一过程降至最低。\n * **减缓化学反应:** 低温降低了溶液中所有化学反应的速率,包括可能导致酶变性的氧化反应或脱酰胺反应等。\n * **维持结构稳定性:** 低温有助于维持胰酶分子的天然三维构象,防止因热运动导致的结构松散和失活。\n * **抑制微生物生长:** 低温(尤其是冷冻)能有效抑制细菌、真菌等微生物的生长繁殖。**这是维持“低内毒素”状态的关键。** 即使初始内毒素很低,如果储存过程中微生物滋生,其死亡裂解后会释放大量内毒素,导致内毒素水平飙升,严重影响细胞实验结果(如激活细胞炎症通路)。低温储存从根本上杜绝了这种污染风险。\n\n2. **分装 (Aliquoting):**\n * **避免反复冻融:** 反复冻融是导致胰酶失活的**最主要杀手**。每次冻融循环都会:\n * 产生冰晶,可能直接剪切酶分子,破坏其结构。\n * 导致溶液局部浓度和pH值的剧烈变化(如冰晶形成时溶质浓缩),加速酶变性。\n * 增加溶液与空气(氧气)的接触机会,促进氧化。\n * 增加污染风险(每次操作都引入污染可能)。\n * **分装确保每次只取出一个 aliquot 使用,用完即弃,避免了剩余消化液经历多次冻融循环**,从而最大程度地保护了酶的活性和溶液的稳定性(包括内毒素水平)。\n\n3. **合适的容器 (无菌、低蛋白吸附、低内毒素):**\n * **防止酶损失:** 低蛋白吸附的容器(如高质量PP管)能最大程度减少胰酶分子在管壁上的吸附,确保溶液中活性酶的浓度保持稳定。\n * **防止污染:** 无菌容器杜绝了初始储存时的微生物污染源。低内毒素容器确保储存过程本身不会引入新的内毒素污染。\n * **防止化学干扰:** 高质量的惰性材料不会释放可能影响酶活性或细胞毒性的化学物质(如塑化剂)。\n\n4. **避光:**\n * 虽然不是主要因素,但避光储存提供了额外的保护层,防止任何潜在的光敏性成分(可能存在痕量杂质)发生光化学反应,避免产生可能影响酶活性或细胞反应的副产物。\n\n5. **密封:**\n * **防止浓缩/稀释:** 密封防止水分蒸发,避免溶液浓度升高(导致消化过强)或吸潮导致浓度降低(导致消化不足)。\n * **防止氧化:** 减少溶液与空气(氧气)的接触,降低氧化导致酶失活的风险。\n * **防止污染:** 密封是防止储存过程中微生物(细菌、霉菌)进入的关键物理屏障,**直接保障了低内毒素状态的维持**。\n\n## 📌 总结与关键点\n\n* **核心是低温冷冻 + 分装:** -20°C 或更低温度储存是抑制酶自降解和微生物生长的基础。分装成小 aliquot 是避免反复冻融失活的**绝对必要措施**。\n* **低内毒素依赖于无菌和防污染:** 低温储存抑制微生物生长,无菌容器和密封操作防止初始和储存过程中的污染,共同确保内毒素水平在有效期内维持在极低状态。\n* **容器选择不容忽视:** 低蛋白吸附和低内毒素的容器材质对维持酶浓度和溶液纯净度至关重要。\n* **遵循说明书:** **最重要的一点是:务必遵循您所使用的具体品牌和批次胰酶消化液产品说明书上提供的储存条件和有效期。** 不同厂家、不同配方(如是否含 EDTA、酚红等)的胰酶消化液,其最佳储存条件和稳定期限可能略有差异。说明书是最权威的指导。\n* **解冻与使用:** 使用时,将所需 aliquot 从冰箱取出,**在冰上或 2-8°C 冰箱中缓慢解冻**。避免室温解冻或水浴加速解冻(温度骤变易失活)。解冻后应立即使用,**切勿再次冷冻**已解冻的 aliquot。使用前可短暂涡旋混匀,但避免剧烈振荡产生气泡(可能导致蛋白变性)。\n\n通过严格遵守这些储存条件,可以最大限度地保证低内毒素胰酶消化液的蛋白酶活性、消化效率以及内毒素水平在有效期内保持稳定,从而为细胞培养实验提供可靠、一致且无干扰的消化效果。💪🏻",
"system": ""
}
]dataset_info.json1
2
3
4
5
6
7
8{
"identity": {
"file_name": "identity.json"
},
"dayou": {
"file_name": "dayou.json"
}
}
基于LoRA的sft指令微调
1 | CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ |
动态合并LoRA的推理
当基于LoRA的训练进程结束后,我们如果想做一下动态验证,在网页端里与新模型对话,与步骤 原始模型直接推理 相比,唯一的区别是需要通过adapter_name_or_path参数告诉LoRA的模型位置。touch examples/inference/qwen2.5_sft.yaml
1 | model_name_or_path: /root/autodl-tmp/LLaMA-Factory/models/Qwen/Qwen2.5-1.5B-Instruct |
- 终端推理:
llamafactory-cli chat examples/inference/qwen2.5_sft.yaml - web推理:
llamafactory-cli webchat examples/inference/qwen2.5_sft.yaml